[Body]
Advanced Parallelizing Compiler Technology Research and Development Project
1 Details of Research and Development, Targets, and R&D Capability
|
1. Details and Targets of the Proposed Research and Development Project
1-1. Overview of Research and Development
To improve effective performance in multiprocessor systems, research and development will be conducted to create an advanced parallelizing compiler (APC) technology that distributes each part of a program to the appropriate grain in a hierarchical manner and automatically extracts parallels from each level. Technologies to evaluate the performance of parallelizing compilers will also be the focus of research and development. The target for the final year of the project is to double performance in multiple shared-memory processors (SMPs) of different types, in comparison with conventional automatic parallelizing compilers that extract parallels in single grains.
1-2. Details of Research and Development and Targets
(Social background)
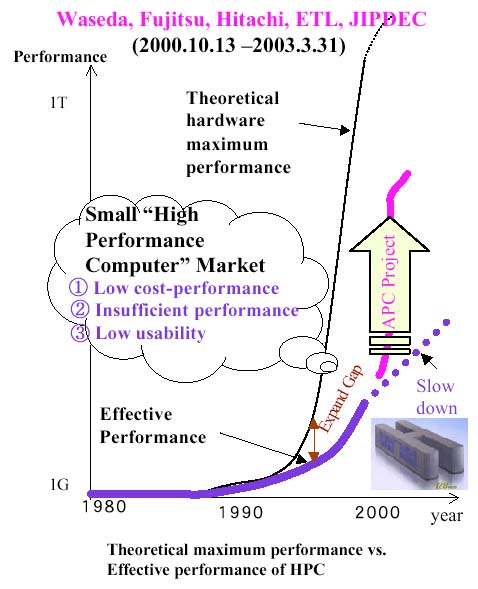
Japanese companies lead the world in the field of high-performance computing (HPC), particularly in the field of supercomputers (vector machines). In the wake of the recent recession, however, domestic customers' appetite for investment in HPC has declined, and problems of low cost-performance and difficulty of use make any effort to broaden the HPC market a formidable challenge. Given the high development cost of these devices, manufacturers are increasingly reluctant to invest in their development.
Meanwhile, the United States continues to maintain a lock on the market for microprocessors, a high-value-added IT product. These existing high-speed microprocessors are now entering the HPC market in the form of mid-range servers, in which several microprocessors are connected in parallel. Mid-range servers enjoy a healthy 5-12% growth rate, and in 1998 they accounted for 80% of the HPC market, or approximately 500 billion yen.
As the demand for processing power grows, the focus in value-added IT systems is expected to shift from the processor to the chip set and to the software that runs it. To support and bolster the competitive strength of Japan's computer industry in the 21st century, the development of high-value-added and easy-to-use software is an issue of critical importance. As parallel-machine configurations grow increasingly prevalent from PCs to HPCs, automatic parallelizing compiler software is emerging as a key technology.
The development of this fundamental software technology will lead to the improvement of the technological strength of Japanese software technology as a whole. It will play a pivotal role in the development of the IT industry, increasing Japan's international competitiveness and job creation. Because the scope of application of this technology is extremely broad, APC will form a fundamental technology in numerous fields, including the computational science used in the biotechnology and automobile industries, development of new energy sources, and energy-saving technologies. Given the strong boost this technology will lend to the science and technology of the 21st century, APC can be expected to spread rapidly over the years ahead.
(Technological background)
As stated earlier, Japan is the world leader vector machines and other hardware in the HPC field. In the early part of the 21st century, Japanese developers are expected to achieve a peak performance of 10 teraflops (10TFLOPS, or 10 trillion floating-point calculations per second). The United States is catching up fast, however: The Accelerated Strategic Computing Initiative (ASCI) project has already met its target, and development of a computer with effective performance at the PFLOPS level (capable of 100 trillion floating-point calculations per second) is planned according to a proposal from the President Information Technology Advisory Committee. In contrast to this concerted plan of attack, Japan has no national HPC project for 2001 and beyond. This state of affairs raises the danger that Japan may be unable to maintain its current international competitiveness going forward.
In the software field, Japan lags far behind the United States in automatic parallelizing compiler technology, which contributes to the effective performance of parallelizing machines. In scalar parallelizing multiprocessor systems, which are expected to emerge as a mainstream computer configuration soon from PCs to HPCs, Japanese technology is only able to elicit effective performance (actual performance when running actual applications) of a few percent of peak performance (maximum performance as listed in the product catalog). This is due to the following problems.
As the number of processors used in multiprocessor systems rises, the gap between peak performance and effective performance widens, decreasing the system's cost-performance.
The market's expansion is constrained because the software is difficult to use, such that only users with extensive knowledge of parallel processing can make full use of multiprocessors.
To break this impasse, important software called automatic parallelizing software (parallelizing compilers and tuning tools that work in close coordination with them) must be developed. With the development of this software, users can elicit a high level of effective performance without being aware of the intricacies of parallel processing. This breakthrough will support Japan's global competitiveness in PCs, workstations and HPCs.
Against this background, the first objective of this research and development project, "development of advanced parallelizing compiler (APC) technologies," refers to the development of automatic multigrain parallelizing technologies and tuning tools that work in close coordination with them, creating a platform-free automatic parallelizing compiler. The second objective, "development of technologies for the evaluation of parallelizing compiler performance," refers to the establishment of methods of evaluating the performance of parallelizing compilers, for which no adequate evaluation methods currently exist. The target for this project is to create through APC research an automatic parallelizing compiler whose effective performance is roughly double that of conventional automatic compilers. In the following section, the details and targets for each theme of research and development are listed.
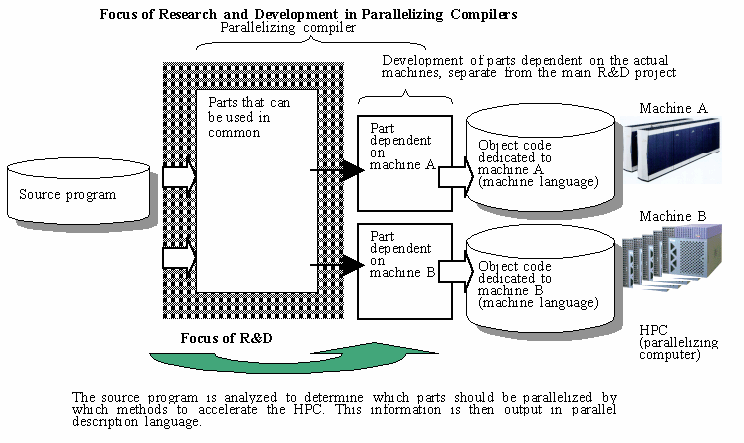
1-2-1. Development of APC Technology
The foci of research and development in this proposal with respect to the parallelizing compiler to be developed are detailed in the illustration below. As the figure shows, this R&D project aims to develop a platform-free automatic parallelizing compiler; parts that are sensitive on the actual hardware used are outside the scope of this project. To evaluate the project, however, several SMPs are required, and inevitably some machine-sensitive parts must also be developed for this purpose. Such development will be carried out in parallel with the R&D project and will be budgeted separately.
(Current Status of R&D and Technological Issues)
1)The automatic parallelizing compilers developed hitherto for HPC multiprocessor systems are based on the loop-parallelizing technology (parallelization that features repeated iteration of the same process) developed in the 1980s at the University of Illinois. As Amdahl's Law indicates, however, portions where loop parallelization is not feasible exert an increasing impact on performance as the number of processors linked in parallel increases. Because of the large number of processors used in the most recent arrays, loop parallelization has reached a hard limit in its capacity for performance improvement.
2)At the microprocessor level, the instruction-level fine-grain parallelizing compilers used in superscalar, Very Long Instruction Word (VLIW) systems have reached an intrinsic hard limit in fine-grain parallelization. Even when four, eight or even more hardware units are arrayed in parallel, the accompanying boost in speed is no higher than three or four times.
Taking all of the above problems into consideration, the most desirable direction to take is the development of scalable automatic parallelizing compilers. This solution could be applied everywhere from the single processors that use parallel processing in mainstream PCs and HPCs (such as single-chip multiprocessors, widely considered a strong candidate to emerge as the leading next-generation processor architecture) to mid-range servers and HPCs in which several such devices are connected. Such compiler technology is called "platform-free" because it can be applied to any multiprocessor architecture.
(Breakthrough points and methods)
1) Multigrain parallelizing technology and speculative running
As described above, researchers have become frustrated by the hard limits to loop parallelization in HPC multiprocessor systems and by the hard limits to instruction-level fine-grain processing in microprocessors. To break through this impasse, single-chip multiprocessors with improved parallelization are needed, to respond to improvements in integration in ULSIs, as well as automatic parallelization technology applied in server and HPC multiprocessor systems, in which a large number of such multiprocessors are linked in an array.
Multigrain automatic parallelizing compiling is an original method in which fine-grain parallels, loop parallels and parallels among subroutines, loops and basic blocks are elicited hierarchically. This method can be combined with the critical speculative running method, which conducts speculative running at the task level. Using these two methods, it is possible to boost the effective performance of next-generation machines from PCs to HPCs and make automatic parallelization of ordinary user programs easy to handle.
2) Automatic data distribution
In order to obtain high performance from multiprocessor systems, high-speed memory such as distributed cache, local memory and distributed shared memory must be held close to the processor. To use this high-speed memory effectively, however, the user must explicitly write instructions in a language such as High Performance Fortran (HPF). This is clearly an onerous requirement for most users. To overcome this obstacle and achieve automatic, high-speed processing without the intervention of the user, automatic data distribution and automatic cache-use optimization technologies are required. When this technology is fused with multigrain parallel processing to produce automatic data distribution technology, the technology can be extended to enable automatic data distribution and cache optimization.
3) Scheduling Technology
Multiprocessor scheduling technology raises the usage rate of multiprocessor systems while minimizing the overhead from data transfer between processors. This technology is a key factor in improving the effective performance of a machine. A compiler technology with high effective performance, fusing multiprocessor scheduling algorithms that minimize running time with technology for overlapping scheduling of task processing and data transfer, is an essential component of APC technology.
The tables on the following pages describe in detail each of the elemental technologies to be developed for APC, by which each of the above breakthrough points can be achieved.
(1) Development of automatic multigrain parallelizing technology
Improving the effective performance of programs to elicit the full performance of multiprocessors requires a combination of parallelization at many different levels. Issues for automatic parallelizing compilers include not only parallelization within single loops in a program but also parallelization of subroutine cores, loops that include subroutine cores and scattered grains between loops, as well as parallelization of fine grains such as sets of basic blocks. To find a solution to these issues, this project targets the development of automatic multigrain parallelizing technology, which automatically elicits parallels in multiple grains in a hierarchical manner.
The most important target of this project is to find practical applications for the automatic multigrain parallelizing technology hitherto developed primarily at universities, and to conduct R&D in each important elemental technology of which automatic multigrain parallelizing is composed. Specific elemental technologies include data-sensitive analytical technologies, such as conditional array data flow analysis technology, used to improve analytical precision; automatic data distribution technologies, such as technologies to change the controls and interprocedural array configurations of data distribution compilers for distributed shared-memory multiprocessors, to improve the reference characteristics of program data; and technologies to set OpenMP extended specifications and generate source programs in those extended OpenMP specifications, to establish a platform-free parallel description language capable of describing memory reference characteristics.
Main issues and final targets, along with related technology items, are shown in the table below.
Main issues and final targets for automatic multigrain parallelizing technologies
|
Technology items
|
Conventional technologies
|
Key issues
|
Final target
|
|
(a) Multigrain parallel extraction technology
|
(1) Lacks extraction of parallels from control structures other than components of loop structures.
(2) Uses only parallels in single grains, such as the instruction level or loop level. Lacks extraction of parallels from multiple levels.
|
(1) Generation of parallel tasks in complex data structures, including pointers, and control structures, such as between loops and between basic blocks
(2) Allocation to and parallelization of the most appropriate grain size for high parallel processing effect in each part of the program
|
(1) The number of parallelized lines of code in one or more of the evaluation programs selected in the final year of the project is at least 50% higher than the corresponding number when only conventional parallelization technology is applied.
|
|
(b) Data-sensitive analysis technology
|
(1) Limitation of Static Data-Dependent Analysis
|
(1) Development of conditional data flow analysis technology
(2) Development of running time-sensitive analysis technology
|
(1) Automatic parallelization of main loops that could not be so processed by Stanford University's Stanford University Intermediate Format (SUIF) compiler, which is the leader in the field, is achieved in one or more of the evaluation programs selected in the final year of the project.
|
(c) Automatic data distribution technology
|
(1) Users must give explicit instructions for data distribution.
|
(1) Development of automatic data distribution technology for use in distributed shared memory systems
(2) Development of automatic data distribution technology for use in distributed cache memory systems
(3) Development of automatic data distribution technology for use in multiprocessor systems featuring local memory and shared memory
|
(1) Performance improvement of 30% or more is achieved in one or more of the evaluation programs selected in the final year of the project, in comparison with cases where this technology is not used.
|
(d) Speculative running technology
|
(1) Speculative running in single grains (at the instruction level) is conducted only within the processor.
|
(1) Achievement of speculative running in multiple grains (medium grains and coarse grains)
|
(1) Performance improvement of 100% or more is achieved in one or more of the kernel benchmark programs selected in the final year of the project, in comparison with cases where this technology is not used.
|
|
(e) Scheduling technology
|
(1) Strong NP is difficult to apply to multiprocessor scheduling problems. As the scale of the problem grows, optimal or approximate solutions are difficult to obtain within a practical running time.
|
(1) Development of methods to address the difficulties of conducting strong NP in multiprocessor scheduling by devising optimal or near-optimal solutions for problems that arise in actual running
(2) Development of scheduling algorithms that take into account overlap between data transfer and task processing
|
(1) Performance improvement of 15% or more is achieved in one or more of the evaluation programs selected in the final year of the project, in comparison with cases where this technology is not used.
|
|
(f) Preparation of an extended parallel description language
|
(1) Current versions of OpenMP lack a description method for the data distribution methods that will be used in the distributed-shared-memory multiprocessors expected to become mainstream products in the near future.
(2) Current versions of OpenMP cannot adequately describe local-data allocation to threads for modules and common block variables.
|
(1) Extended indication of data distribution in distributed shared memory multiprocessors
(2) Development and evaluation of technology to generate and enter source programs for extended OpenMP specifications, based on these specifications
(3) Extensions that can be used as an intermediate language for exchange of data analysis between modules of a platform-free APC
|
(1) Use of an extended version of OpenMP as an intermediate language is enabled for use in exchanging analysis data between modules of the platform-free APC to be completed in the final year of the project.
(2) Performance improvement of 30% or more is achieved in one or more of the evaluation programs selected in the final year of the project, by generating source programs with extended OpenMP specifications, in comparison with cases where optimization by hand is not conducted.
|
(a) Multigrain parallel extraction technology
As with multigrain parallelization, effective parallel processing of multiple grains in a hierarchical fashion requires that solutions be found to the following technological problems.
- How should hierarchical extraction be carried out? From which grains, and from which parts of the program?
- What sort of processor clustering should be conducted to ensure effective use of the extracted parallels?
In conventional parallelization methods, parallelization targets are restricted to calculation of iterations in loop structures in simple array data. Loop restructuring techniques such as data privatization and unimodular conversion enable further parallels to be extracted from these parts. Nonetheless, in many cases parallelization is not feasible in more complex loops or in loops that include pointers, and is inadequate in non-loop structures such as subroutines, interloops and basic blocks.
In light of these present conditions, the following will be carried out in this R&D project:
1) Automatic parallel extraction technology will be developed to enable extraction of parallel tasks from complex data structures (including interfaces) and control structures such as interloops and basic blocks. To make such parallel task extraction possible, data-sensitive analysis and control-sensitive analysis will have to be carried out as strictly as possible in data structures that include pointers, with a wide scope that includes interfunctions. This data-sensitive analysis and control-sensitive analysis will be carried out as part of this project.
2) Technology will be developed to determine grains automatically, for use in hierarchical multigrain parallel processing. For this purpose, task generation technology will be developed for enhancement of data-sensitive analysis, including interprocedural analysis, as well as for effective use of distributed shared memory, distributed cache and local memory. R&D will also be conduced in process clustering methods, to maximize the use of hierarchical task parallelization.
Final target
The target is to increase by at least 50% the number of parallelized lines of code in the source code, in comparison with the case in which only conventional technology is used, in at least one of the evaluation programs selected in the final year of the project.
Social implications of targets
In parallelizing compiling technologies developed hitherto, programs that succeeded in boosting performance through parallelization conformed to a tightly restricted set of patterns. By applying the technology developed in this project, the parallelization in previously parallelized application programs can be improved, leading not only to improved running speed but to a widened scope of parallelizable programs. The significance of this development for industry is great, as parallel computers come to be applied in a wide range of new fields.
Technological implications of targets
This technology extracts an entire range of parallels that cannot be obtained from conventional parallelization methods, presenting a wholly new perspective on parallelization and testifying to the novelty of this approach. The authors believe that the target of this project, a 50% or greater increase in the number of parallels extracted in comparison with the already mature loop-parallelization technology, is a sufficiently high and significant target.
(b) Data-sensitive analysis technology
Much research and development has been conducted on data-sensitive analysis technology. Most of this research has focused on nonlinear subscript analysis based on tests such as the greatest-common-divisor (GCD) method, Banerjee's inexact and exact tests, the OMEGA test and symbolic difference, and on static analysis such as array private analysis based on various array regions. Even using the data-sensitive analysis technology already proposed, however, analysis is quite time-consuming, and the difficulty of development is out of proportion to the narrow range of application. Due to these problems, much research in this field has gone no further than experiential development and evaluation in university laboratories, and is not sufficiently applied to compilers at the practical level. The present R&D project will conduct research and development in conditional data flow analysis technology. In this technology, the conditions for generating data sensitivity between array references are generated statically during compiling; during running, these conditions are used as judgment criteria; this information is then used to select between parallelization code and sequential code. In addition, R&D will be conducted in running-time-sensitive analytical technology, in which data-sensitive analysis itself is conducted. Finally, by fusing all of these R&D efforts, the precision of analysis will be boosted and data-sensitive analytical technology with low running-time overhead will be achieved.
Final target
By combining conditional data-flow analysis with running-time-sensitive analysis, this project aims to achieve automatic parallelization of main loops that could not be so processed by Stanford University's SUIF compiler, which is the leader in the field, in one or more of the evaluation programs selected in the final year of the project.
Social implications of targets
Many programs are theoretically capable of parallelization but in practice only parallelization through static analysis is achieved during compiling. In programs such as these, this technology can be applied to provide automatic parallelization, requiring no intervention by the user. The effective performance of the multiprocessor can thus be easily improved, delivering excellent results across entire industries.
Technological implications of targets
One of the most advanced compilers in this field is SUIF, developed by Stanford University, the leader in this area in the United States. The researchers believe that their target of exceeding the performance of the SUIF compiler is a sufficiently ambitious target.
(c) Automatic data distribution technology
Data distribution is a supporting factor in the performance of distributed-memory multiprocessors. Because automatic data distribution is not expected to provide sufficient performance, currently most users write explicit instructions by hand for data distribution. HPF, for example, is a typical language used to describe parallel programs based on explicit data distribution by the user. However, to describe data distribution using HPF, the entire program must first be rewritten according to HPF grammar. This rewriting is much more time-consuming than the data distribution description itself, and consequently HPF has had little success in the market. Clearly, therefore, research and development is urgently needed to create an automatic data distribution technology that can optimize data distribution without requiring programs to be rewritten.
The following research and development will be conducted in this project.
1) Data distribution technology for distributed shared memory
In comparison with distributed-memory multiprocessors, the differences in performance that arise from the data distribution methods used are thought to be slight in distributed shared memory (DSM). Another alternative is software-based DSM, which achieves "virtual" DSM performance in multiprocessors. This project conducts R&D in automatic data distribution technology for both of these types of DSM systems, based on automatic control technology for data distribution in the compiler and technology to change the structure of interprocedural arrays.
2) Data distribution technology for distributed cache memory
To use the memory layer effectively, the researchers will develop automatic data distribution technologies, which establish a data layout that minimizes cache error, and loop conversion technologies, which conduct grain conversion in tasks. In machine models such as SMP and cache-coherent non-uniform memory architecture (CC-NUMA), parallel control technologies will be developed to enable these technologies to be combined for optimum effect.
3) Data distribution technology for multiprocessor systems that have both shared memory and local memory
In multigrain parallel processing, dynamic scheduling is applied to coarse-grain tasks. Generally the data shared among these coarse-grain tasks is located in a central, shared memory. To achieve high effective performance, a technology is urgently needed that automatically distributes data to local memory and transfers data through local memory, reducing data transfer overhead. This research project, conducted in a dynamic scheduling environment, develops methods of distribution of data processing and dynamic scheduling to achieve data transfer between coarse-grain tasks through local memory, over a wide scope in the program.
Final target
The data distribution technology developed in this project aims to achieve performance improvement of 30% or more in one or more of the evaluation programs selected in the final year of the project, in comparison with cases where this technology is not used.
Social implications of targets
DSM multiprocessors have attracted considerable attention as a promising next-generation multiprocessor, because they support data distribution without rewriting of programs and offer scalability according to the number of processors. Every major processor manufacturer is working on product development incorporating DSM multiprocessors, and this technology appears set to emerge as a mainstream technology in the near future. The industrial significance of this R&D project is therefore exceptionally high. The researchers are convinced that their target of a 30% improvement in performance over conventional technologies is sufficiently ambitious and will break important new ground in the field of DSM multiprocessors.
To eliminate differences in speed between processors and memory, most modern computer systems use a hierarchical memory configuration. Obtaining effective use of this hierarchical memory configuration will greatly improve the performance of a vast range of computer systems, underscoring the importance of this technology for Japan's industries.
Technological implications of targets
DSM is believed to be unaffected by differences between data distribution methods. Depending on the program being run, however, differences in data distribution may cause as much as a 50% discrepancy in performance. The researchers feel that their target of a 30% improvement, being equal to 60% of this 30% discrepancy, is an appropriate technological target.
In actual parallel running, cache errors cannot always be avoided, so data distribution cannot be expected to boost performance in all programs. Nonetheless, it is well known that cache errors account for about 50% of overhead in many programs. The target established for this project is therefore an appropriate target, as it represents the automatic elimination of 60% of those errors.
(d) Speculative running technology
In the past, if parallels did not reside in the program itself, the only method of parallelization available was parallel running. To accelerate running of these parts of the program, this project will develop methods of speculative running. Conventional speculative running focuses only on the instruction level, where techniques such as branch prediction are used within the processor. This project goes much further, conducting R&D to perform speculative running at the task level (between loop and non-loop portions, for example), as well as speculative running using multiple grains at once.
Specifically, of the fine, medium and coarse grains that are the focus of multigrain parallelization technology, the speculative running technology developed in this project involve the medium-grain (loop) and coarse-grain (subroutine, loop, basic-block) levels. In particular, technology to extract parallels between coarse grains, where static extraction of parallels with uniform grain sizes is more difficult than in loop portions, is absolutely essential, since the non-loop portion accounts for roughly half of total running time. It is in this area that speculative running will be most effective.
This project will conduct research and development in a number of areas of speculative running, of which the following are a few examples. In task selection technology, decisions are made as to which tasks are made the object of speculative running. Speculative dynamic task scheduling technology determines when speculative running is started, while speculative task retrieval technology ends unnecessary speculative tasks. Finally, task generation technology raises the effective performance of speculative running, and data prediction technology takes the effective performance of speculative running into account.
Final target
The effects of speculative running will inevitably be much more pronounced in some programs than in others. For this reason, the target for this technology is to achieve performance improvement of 100% or more in one or more of the kernel benchmark programs selected in the final year of the project, in comparison with cases where this technology is not used.
Social implications of targets
The overall target for this project is a 100% improvement in performance. The target for the development of this technology is to achieve this final target in at least one of the benchmark programs, using speculative running only, without upgrading or modifying the hardware. Because of the wide applicability of this speculative running technology, the effects on industry are expected to be high.
Technological implications of targets
If SMP devices, which are widely commercially available and do not possess special hardware to support speculative running, are used as the platform for this technology, it is clear from previous research that the use of speculative running will actually slow processing down due to higher task control overhead if speculative running offers no ultimate benefits. In tests using toy programs, acceleration as high as 10 _ has been confirmed under ideal conditions for adequate benefits from speculative running (using 80 processors). However, when the overheads involved in commercializing this method are taken into consideration, the researchers conclude that a 100% improvement in performance is a sufficient target.
(e) Scheduling technology
Multiprocessor scheduling technology allocates to each processor the task sets that are generated after parallels are extracted from the program and parallel processing grains are determined, in such a way as to minimize processing time. This technology is essential for improving the effective performance of multiprocessor systems. The problem of scheduling, which is a crucial part of compiler technology, is one of the most intractable problems in optimizing so-called "strong NP" combinations of hardware. Scheduling problems are normally thought to render solutions using polynomial time optimization algorithms impossible (if they properly belong to the class P not equal to NP). Consequently, more practical algorithms, which offer practical solutions to actual problems, must be developed. To achieve this objective, this project will focus on the examination of optimization algorithms that quickly provide the optimum solution to multiple problems, as well as heuristic algorithms, in which optimization cannot be assured but no problems of practical application arise. In particular, heuristic algorithms will be developed that eliminate overhead from data transfer by overlapping data transfer between processors and task processing on the same processor, thus reducing overall processing time. Also, the task and data-transfer technologies that will be developed to overlap the data transfer and task processing will be used not only in architectures possessing both DSM and a data transfer controller on each processor, but also in fixed-length and variable-length pre-fetch scheduling for distributed cache on single-chip multiprocessors.
Final target
Scheduling algorithms will be developed that can be included in compilers that reduce processing time, given overlap of data transfer and task processing. When the performance of these scheduling algorithms is evaluated, the improvement in performance will vary dramatically according to such factors as the task processing time and volume of data transferred between tasks in a given application program, as well as the data transfer performance, synchronous performance, task processing performance, intertask parallelization and number of processors of the multiprocessor system. Moreover, it is impossible to double the performance of a multiprocessor system without changing the number of processors and only changing the task and data-transfer allocation method (the scheduling method). In addition, currently commercially available shared-memory multiprocessors do not support control of prefetch from the cache using advanced languages such as OpenMP. Therefore, the final target of this project is to achieve performance improvement of 15% or more in one or more of the benchmark programs selected in the final year of the project, in comparison with cases where this technology is not used, in a multiprocessor or realistic simulator whose structure supports overlap of data transfer and task processing.
Social implications of targets
In today's computers, advances in memory speed have failed to keep pace with improvements in processor clock speed. This is why, in multiprocessor systems equipped with central or shared memory capable of data transfer between processors, the overhead of such data transfer grows increasingly pronounced year by year in comparison with distributed-memory multiprocessors. In the multiprocessor systems of the future, including general-purpose and combined-purpose single-chip multiprocessors, minimization of this overhead of data transfer between processors and equalization of the load between processors to equalize processing time will be vital in obtaining maximum performance from the hardware. This effort is crucial in maintaining the competitiveness of Japan's multiprocessor industry, from single-chip multiprocessors to HPCs.
Technological implications of targets
The lag in memory access speed in comparison with processor operation speed is an unavoidable problem in all multiprocessor systems, from single-chip multiprocessors to HPCs. In this R&D project the researchers intend to eliminate this problem by minimizing data transfer volume; equalizing processor load; and conducting such data transfer as cannot be avoided in conjunction with task running. This project therefore conducts research and development in methods to overlap data transfer between processors with task processing, controlled by the compiler. Even if shared-memory multiprocessor systems as described above do not become commercially available by the final year of the project, it is certain that the single-chip multiprocessors expected to be commercialized by the end of the first decade of the 21st century and the coming next-generation HPCs will possess such architecture. Therefore, if performance evaluation cannot be performed on commercially available multiprocessor systems, such performance must be tested on realistic simulators. The researchers believe that a performance improvement target of 15% is a sufficiently high target, given that the best technical items are selected from combinations of task sets with the same parallels allocated to processors.
(f) Preparation of an extended parallel description language
OpenMP is attracting wide attention as a platform-free program description language. OpenMP is a parallel description specification for shared-memory multiprocessors. By describing parallelizing loops and the start and stop points of portions where parallels are run, OpenMP enables the description of highly efficient parallelization methods. Unfortunately OpenMP in its present form suffers a number of drawbacks. It does not support description of distributed-data methods used in DSM multiprocessors, which are expected to become the mainstream computing products of the future, nor does it provide sufficient description of local data assignment to threads for variables described in modules and common blocks.
This project will prepare extended specifications for OpenMP to enable parallelizing description of portions where OpenMP is currently unable to provide parallelization (such as design of extended specifications for memory-layer expression formats, hierarchical parallel processing and speculative running). Using these new specifications, the project will then develop and evaluate technologies to generate source programs with extended OpenMP specifications. By using a standard parallel description language as an interface, the technologies developed in this project will be evaluated on a wide variety of machines, enabling the phased combination of multiple technologies.
Final target
The final target of this part of the project is to enable extended OpenMP to be used as an intermediary language for the exchange of analytical data between parallelizing compiler modules (between analytical paths) in the platform-free APC to be developed by the final year of this project.
To evaluate the descriptive performance of extended OpenMP, a source program will be generated using the extended OpenMP specifications and a program rewritten by hand based on the extended OpenMP specifications will be evaluated in one or more of the evaluation programs selected in the final year of the project, Performance improvement of 30% or more is expected to be achieved in comparison with cases where optimization by manual work using extended OpenMP is not used.
Social implications of targets
Platform-free parallelizing description language is important for eliciting improved performance from multiprocessors independently of the type of compiler used, and therefore holds the key to expanding the adoption of multiprocessor technology. By providing this parallelizing description language for the input and output of each module (analytical path) of the APC to be developed in this project, this technology will contribute significantly to the increased use of multiprocessors.
Technological implications of targets
When this technology is applied in DSM computers, the performance of said computers is expected to become less vulnerable to the effect of differences between data distribution methods. Depending on the program, the discrepancy in performance could be as high as 50%. The researchers feel that their target of a 30% improvement, being equal to 60% of the 50% discrepancy resulting from use of extended OpenMP, is an appropriate technological target for the descriptive performance of the language.
(2) Development of parallelizing tuning technologies
Programs often require tuning to reduce the amount of time the user has to spend with the program and, in programs that use dynamic information that can only be obtained through interaction with the user or when the program is running, to improve the effective performance of parallelization. To solve these issues, this project aims to establish parallelizing tuning technologies to enable the application of interactive and dynamic information.
This aspect of the project consists of research and development in three technologies. Program visualization technology displays a variety of data required by the user, such as program structure and factors that block parallelization, in an easy-to-understand graphic form. Dynamic information application technology captures dynamic information that can only be obtained while the program is running, such as running profiles data-sensitive analytical results during running, and applies this dynamic information to program tuning. Finally, combined parallelization technology provides the user with information that the compiler cannot determine statically and supports the optimal combination of multiple parallelization technologies by automatically testing various combinations.
The final targets for each major issue and the individual technologies applied to each are given in the following table.
Main issues and final targets for parallelizing tuning technologies
|
Technology items
|
Conventional technologies
|
Key issues
|
Final target
|
|
(a) Program visualization technology
|
(1) Program parallelizing tuning by anybody other than the original author of the program is extremely time-consuming.
|
(1) Program visualization technology must make data required for tuning easy to retrieve and offers an easy bird's-eye view of parallel structures in programs.
|
(1) Reduction of 50% or more is achieved in time taken to conduct surveys of parallelization tuning in various programs in one or more of the evaluation programs selected in the final year of the project, in comparison with cases where this technology is not used.
|
(b) Dynamic information application technology
|
(1) Some tools for individual measurement of dynamic data exist, but their applicability to program tuning support and feedback to the compiler are inadequate.
|
(1) Dynamic information application technology used in general program tuning is conducted, including feedback to compiler optimization of dynamic information obtained during program running
|
(1) Performance improvement of 20% or more is achieved semi-automatically in one or more of the evaluation programs selected in the final year of the project, in comparison with cases where this technology is not used.
|
|
(c) Combined parallelization technology
|
(1) Optimization of combinations of individual parallelizing technologies is not available.
|
(1) Technology is developed that contributes to optimal combination of multiple parallelization technologies, through automatic combination of multiple parallelization technologies and combination of parameter fields.
|
(1) Performance improvement of 20% or more is achieved semi-automatically in one or more of the evaluation programs selected in the final year of the project, in comparison with cases where this technology is not used.
|
(a) Program visualization technology
When conducting parallelizing tuning of a program, the user must spend an inordinate amount of time surverying program structure, factors preventing parallelization and data reference characteristics from the point of view of parallelization. If this program parallelizing tuning is done by anybody other than the original author of the program, the process is extremely time-consuming. Program visualization technology uses tools such as a graphical user interface are important because they make this work easier and reduce the time required to survey the program. In this aspect of the project, R&D is conducted in program visualization technologies that render the program parallelization structure easier to grasp and make the information required for tuning easier to elicit.
Final target
The target for this aspect of the project is to achieve a reduction of 50% or more in time taken to conduct surveys of parallelization tuning in various programs in one or more of the evaluation programs selected in the final year of the project, in comparison with cases where this technology is not used.
Social implications of targets
Program parallelizing tuning requires an inordinate amount of time, much of which consists of surveying the program. By applying this technology, parallelizing tuning time can be dramatically reduced, so that the effective performance of a wide range of programs can be dramatically improved within a short time frame. The researchers believe that a reduction in tuning time of 50% is a sufficiently ambitious target.
Technological implications of targets
Although it is difficult to quantify the effect of introducing a graphical user interface, the researchers believe that a reduction in tuning time of 50% is a sufficiently ambitious target.
(b) Dynamic information application technology
Program tuning requires the examination of many forms of dynamic information-data that can only be obtained when the program is running. Such information includes the values assigned to program variables when the program is running, probability of branching, and whether data sensitivity is actually generated by analysis of running-time sensitivity. Research into tools and functions to measure such individual data has been conducted in the past, but its applicability to program tuning support and feedback for compiler optimization were insufficient. In this project, research and development will be conducted in technology for general application of dynamic information obtained during program running to program tuning, including feedback to compiler optimization. In addition, types of dynamic information and format designs will be listed and a compiler interface prepared.
Final target
The final target for this aspect of the project is to achieve performance improvement of 20% or more semiautomatically in one or more of the evaluation programs selected in the final year of the project, in comparison with cases where this technology is not used.
Social implications of targets
Semiautomatic feedback of dynamic information to the user and the compiler is important to simplify parallelizing tuning and to promote development of programs for multiprocessor systems. The researchers believe that improvement of 20% is both a necessary and sufficient target for the commercialization of this technology.
Technological implications of targets
This "semiautomatic" dynamic information application technology will achieve a 20% improvement in the application of dynamic information, which the researchers believe is more than sufficient to make the technology worth using.
(c) Combined parallelization technology
Although a wide range of parallelization technologies have been developed, each was aimed at achieving the highest possible effectiveness on its own, usually with little thought given to their application to other parallelizing technologies. As a result, the effectiveness of individual parallelization technologies falls sharply when used in combination, if the two technologies are used in the wrong order, as the application of one technology tends to render the other inoperable. Also, in various parallelization technologies that operate within the compiler, a number of parameters can be set, and if these parameters are not set correctly their performance may be insufficient. To address these problems, this project will conduct research and development of a combined parallelization technology that optimizes combinations of various parallelization technologies. This will be accomplished by asking the user for information that cannot be determined statically by the compiler, and by automatically trying different combinations of parallelizing technologies and parameters.
Final target
The final target for this aspect of the project is to achieve performance improvement of 20% or more semiautomatically in one or more of the evaluation programs selected in the final year of the project, in comparison with cases where this technology is not used.
Social implications of targets
This project will enable program tuning to be conducted semiautomatically, where previously it had to be done completely by hand. Moreover, by making powerful tools available for selecting optimum combinations and parameter values, parallelization technologies can be optimally combined semiautomatically, enabling half of the tuning work to be done mechanically. The broader social implications of this technology are large. The researchers feel that an improvement of 20% is a necessary and sufficiently high target for commercialization of this technology.
Technological implications of targets
This semiautomatic achievement of a 20% improvement in performance is more than sufficient to make this technology worth using.
1-2-2 Development of Technologies for the Evaluation of Parallelizing Compiler Performance
This project will establish technologies that provide impartial evaluation of the performance of APC systems, such as the automatic multigrain parallelizing technology that performs parallel processing in SMP systems. Specifically, a format that uses benchmarks to evaluate performance on actual systems will be adopted, so benchmark programs, run rules and evaluation indices will be selected to ensure fair and objective performance evaluation. Because APC technology involves the integration of fairly independent individual functions, individual functions will be evaluated by developing benchmarks from kernels and compact applications, while general performance evaluation will be provided by development of benchmarks from full-scale applications.
One of the most widely adopted approaches to evaluation of the performance of computer systems consists of measuring the running time of a benchmark program on an actual machine. Unfortunately none of the benchmarks now available specifically focus on evaluating the performance of parallelizing compilers, so evaluation of parallelizing compiler performance has to be conducted using benchmarks that evaluate the performance of the CPU, the entire system, or parts thereof.
Although the use of such benchmarks to measure the performance of compilers is not inappropriate in itself, the criteria by which benchmarks are selected are still vague. Consequently, the information published in performance evaluation reports on the rules of running and the setting of conditions is never sufficient.
In some cases it is not possible to reach a consensus on which individual functions contribute most to performance. For example, in the SWIM program of the SPEC CPU95fp benchmark, simple loop parallelization appears to achieve something close to hardware peak performance, and so is of little use in evaluating individual functions of the parallelizing compiler. In contrast, the FPPPP program of the SPEC CPU95fp benchmark indicates that little or no improvement in performance is possible no matter how the parallelizing compiler is optimized, due to hardware constraints. This benchmark delivers completely different results but is equally useless in evaluating parallelizing compiler performance.
This project will conduct research and development in benchmarks for evaluation of the performance of APC systems such as the automatic multigrain parallelizing compilers used in SMP systems. This effort consists of 1) preparation and selection of benchmark programs, 2) setting of run rules and 3) setting of measurement indices. The final targets are as follows. By using these benchmarks to evaluate R&D item 1), this project aims to establish technology that can provide objective evaluation of the performance of parallelizing compilers.
The final targets for each major issue and the individual technologies applied to each are given in the following table.
Main issues and final targets for technologies for the evaluation of parallelizing compiler performance
|
Technology items
|
Conventional technologies
|
Key issues
|
Final target
|
|
(1) Development of methods for evaluation of individual functions
|
Evaluation of hardware performance only
|
Technologies are developed to evaluate the performance of individual functions of the data analysis methods and scheduling methods used by the compiler.
|
To evaluate individual functions of parallelizing compilers (testing for presence of functions and the capabilities of individual functions), kernel benchmark programs are prepared, or parts are selected from existing benchmark programs and applications as compact application programs.
|
|
(2) Development of methods for evaluation of general performance
|
Evaluation of general performance, making no distinction between hardware performance and compiler performance
|
Technologies are developed for hardware-independent evaluation of compiler performance.
|
Existing benchmark programs and application programs are selected as full-scale application benchmark programs for use in evaluating general parallelizing compiler performance, taking code scalability indices and performance portability indices into consideration.
|
(1) Development of technologies for the evaluation of individual functions
This project will conduct research and development in methods of evaluation of the individual functions held by compilers. Programs that test for the grains used in automatic multigrain parallelization and for the presence and effect of individual functions, such as data-sensitive analysis technology, speculative running technology and automatic data distribution technology are prepared as kernel benchmark programs (including items other than loops). Existing benchmark programs and parts of applications are selected as compact application benchmark programs.
In conducting R&D into these methods, the following items will be examined with respect to establishing important rules of running, to ensure that the performance evaluation is carried out in an objective and fair manner.
- Extent and levels of authorization for manual insertion of compiler directives into the source code and changes to the source code
- Methods of setting compiler options (types and degrees of optimization/parallelization): Limits on the number of options that can be set, whether or not optimal compiler options can be set individually for each program
- Running environment: data size, number of processors, operating system (system tuning parameters such as single-user/multi-user, stopping/starting of daemons and page size)
Measurement indices for performance evaluation will not merely measure running time under specific environments. The types of indices needed will be examined and clarified. For example, code scalability indices may be generated, indicating how performance changes when programs are run with different numbers of processors, or performance portability indices may be generated, indicating how performance changes when programs are run on different systems.
This research and development project must solve the following problems.
- The fairness and reasonableness of the benchmark programs must be recognized with respect to who developed them, who selected them and how they were collected.
- It must be easily verifiable that the results of running the program are reasonable and that margins of error fall within acceptable bounds.
- Additions other than the source code of the benchmark program (program running results, functions for self-checking of running results, data sets, documents, methods of calculation of performance indices) should be provided in an easy-to-use application software package form.
If actual application programs are to be used as benchmark programs, the following problems must be solved.
- Programs that are widely used in the market may be difficult to obtain for free. Publication and distribution may also not be allowed for security or secrecy reasons.
- With large-scale application programs, upgrades and the like tend to raise maintenance costs.
- A great deal of labor may be required to port an application from one computer to another.
- If a benchmark program is used on many computers, the programming language used to describe it must be a standard language.
Final target
To evaluate individual functions of parallelizing compilers (testing for presence of functions and the capabilities of individual functions), kernel benchmark programs are prepared, or parts are selected from existing benchmark programs and applications as compact application programs, taking indices such as code scalability indices and performance portability indices into consideration.
(2) Development of methods for evaluation of general performance
This project will conduct research and development in methods of evaluating the general performance of compilers independently of the configuration or performance of the hardware. Existing benchmark programs and application programs are selected as full-scale application benchmark programs, and parts of full-scale applications and compact applications that model the actions of full-scale applications are also selected. In selecting these programs, the present technological level of the compiler is considered, and the target in use at that time for development of compiler technology is stated and selected for use in promoting technological development.
In conducting R&D into these methods, the following items will be examined with respect to establishing important rules of running, to ensure that the performance evaluation is carried out in an objective and fair manner.
- Extent and levels of authorization for manual insertion of compiler directives into the source code and changes to the source code
- Methods of setting compiler options (types and degrees of optimization/parallelization): Limits on the number of options that can be set, whether or not optimal compiler options can be set individually for each program
- Running environment: data size, number of processors, operating system (system tuning parameters such as single-user/multi-user, stopping/starting of daemons and page size)
Measurement indices for performance evaluation will not merely measure running time under specific environments. The types of indices needed will be examined and clarified. For example, code scalability indices may be generated, indicating how performance changes when programs are run with different numbers of processors, or performance portability indices may be generated, indicating how performance changes when programs are run on different systems.
This research and development project must solve the following problems.
- The fairness and reasonableness of the benchmark programs must be recognized with respect to who developed them, who selected them and how they were collected.
- It must be easily verifiable that the results of running the program are reasonable and that margins of error fall within acceptable bounds.
- Additions other than the source code of the benchmark program (program running results, functions for self-checking of running results, data sets, documents, methods of calculation of performance indices) should be provided in an easy-to-use application software package form.
If actual application programs are to be used as benchmark programs, the following problems must be solved.
- Programs that are widely used in the market may be difficult to obtain for free. Publication and distribution may also not be allowed for security or secrecy reasons.
- With large-scale application programs, upgrades and the like tend to raise maintenance costs.
- A great deal of labor may be required to port an application from one computer to another.
- If a benchmark program is used on many computers, the programming language used to describe it must be a standard language.
Final target
The final target for this aspect of the project is to select existing benchmark programs and application programs for use as full-scale application benchmark programs, taking indices such as code scalability indices and performance portability indices into consideration.
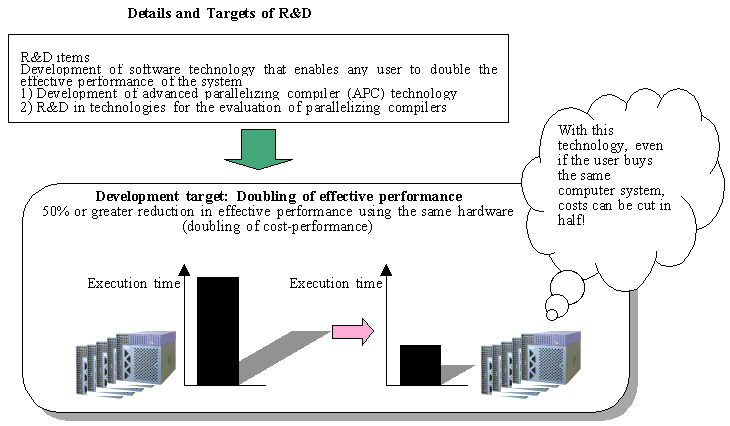
1-2-3. General Targets
To evaluate the technologies developed in 1-2-1, the evaluation technologies developed in 1-2-2 are applied using several multiprocessor systems. In so doing, the final target of this R&D project is to double effective performance in comparison with conventional automatic parallelizing compilers that extract parallels in single grains, even when the technology is operated by users with no specialized knowledge of parallel processing.
(Appropriateness of targets)
Another way to view this doubling of effective performance is to say that the same effective performance is obtained using half the number of processors or fewer. Such an enhancement would reduce the cost of hardware by a similar 50%, which would clearly represent a dramatic boost in system cost-performance. Since this revolutionary result would greatly augment the international competitiveness of related products, the researchers feel that the Japanese public will readily understand the significance of this target.
The above target, in which effective performance (actual performance in running programs) is improved 100% or more in comparison with the case in which the technology developed in this project is not used, indicates a maximum effective performance. This software-based improvement target is much more difficult to meet than a target for improvement in hardware performance, such as increasing processing speeds to TFLOPS or PFLOPS.
For example, in a compiler using this parallelizing compiler technology, if a program can already achieve 80% of hardware maximum performance, doubling that performance is impossible. Therefore, this doubling of effective performance is only theoretically possible in applications whose effective performance is no more than 50% of theoretical maximum performance using currently available parallelizing compilers. Conversely, in applications to which automatic parallel processing is extremely difficult to apply, actual effective performance may be no higher than 30%; in cases such as these, the APC must deliver effective performance at least double that achieved using conventional parallelizing compilers. Therefore, the "doubling" or "100% improvement" specified here represents an exceptionally ambitious target. Nonetheless, to establish a world-leading level of technology, this R&D project must spare no effort to strive toward this daunting goal.
<Necessary conditions>
To achieve the effective performance of current supercomputers on multiprocessor systems, effective performance must be at least doubled over present levels.
<Improvement of cost-performance>
Doubling of effective performance means that the performance provided to the user is increased with no increase in hardware cost, resulting in an increase in cost-performance.
<Improvement in convenience>
The use of the automatic parallelizing compiler and tuning tools developed in this project will significantly simplify parallelization and improve the ease of use of parallelized programs.
<Feasibility>
This R&D project aims to develop the world's first commercial automatic multigrain parallelizing compiler. If this technology succeeds in enabling hierarchical parallelization of which conventional technology is incapable, the effective performance of systems from PCs to HPCs can be doubled.
The following figure illustrates the structure of the platform-free APC created through this R&D project.
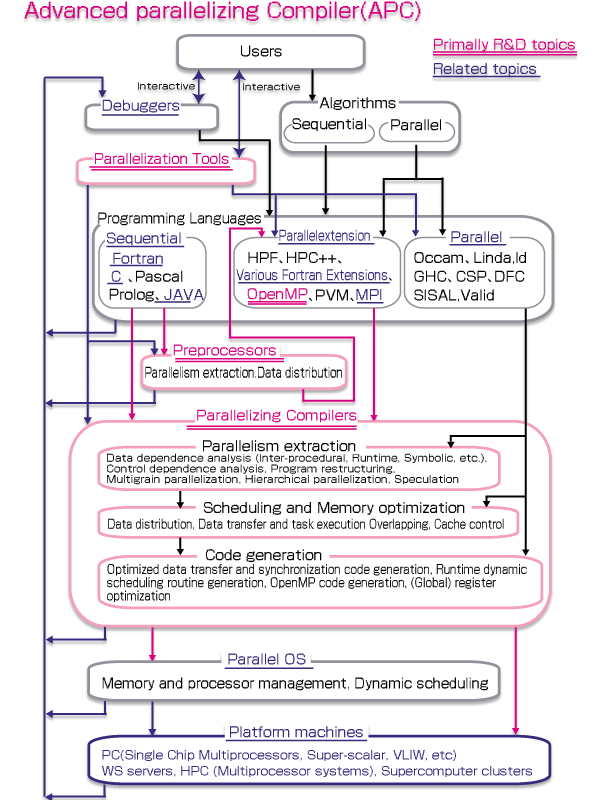
1-3 Research and development Plan
2. Research and Development Capability
2-1. Research and Development Track Record
This R&D project is to be conducted by a team of researchers seconded from JIPDEC, Hitachi and Fujitsu. Some research will be subcontracted to a number of universities (Waseda University, The University of Electro-Communications, Tokyo Institute of Technology, and The Toho University) or conducted through joint research with the Electrotechnical Laboratory. In the following section, this report looks at the research and development track record of each organization. The research results of each university can be found in each individual proposal. Similarly, the track record of the Electrotechnical Laboratory is described in that organization's proposal.
(1) Japan Information Processing Development Corporation
In preparation for pioneering research in ultra-high-speed computing with a target date of 2010, JIPDEC commissioned a preliminary survey from the Mechanical Systems Promotion Council, entitled "Preliminary Survey of Supercompiler Systems," from 1997 to September 1998. To conduct this survey, a Supercompiler Systems Technology Survey Research Committee was established. The survey accomplished the following:
1) A survey of improvements in the effective performance of supercompilers of various architectures, summarizing industrial, technological and government policy issues regarding vector supercomputers, massively parallel computers and ultradistributed computing systems
2) A survey of applications for existing vector and massively parallel computers and applications for next-generation ultra-wide-area distributed computing systems
3) A symposium entitled "Toward Ultra-wide-area Distributed Computing in 2001"
This symposium provided a snapshot of the latest research in North America and Asia and established widespread recognition of the urgency of conducting rapid and organized research in technologies that apply ultra-wide-area distributed computing.
During the two-year period 1998�99, the Organization for General Development of New Energy Sources and Industrial Technologies conducted a survey of supercompiling technologies. On this basis, pioneering survey and research work on supercompiling technologies was conducted, this time with the aim of forming a project to develop core elemental technologies for ultra-high-speed computing systems of the next generation. Technological issues were investigated and the formation of a research organization consisting of members from industry, academia and government was explored. This survey and research work was led by a Supercompiler Technology Survey and Research Committee, and a Parallel Compiler Working Group and Wide-area Distributed Computing Working Group were established under its supervision.
The Parallel Compiler Working Group conducted a detailed survey of trends in the automatic parallelizing compiler technology at the heart of parallel processing software. This survey set five themes for research and development:
1) Multigrain parallelizing technology, which parallelizes programs by hierarchically distributing each part of a program to the optimal grain for parallel processing effect
2) Speculative running technology, including task levels
3) Automatic data distribution technology, which distributes data optimally without instructions from the user
4) Scheduling technology that supports multigrain technology
5) Tuning technology based on dynamic program behavior data
In addition, because existing benchmark tests were inadequate to evaluate the individual functions or general performance of parallelizing compilers, it was determined that technologies for the evaluation of parallelizing compilers would have to be established.
The Wide-area Distributed Computing Working Group conducted the following studies:
1) Examination of specific network technologies involved in cooperative processing of wide-area distributed data
2) Examination of distributed-object technologies and distributed high-performance computing technologies
3) A survey of research and development in the fusion of wide-area networks (WANs) and computers to create ultra-high-speed processors; progress in this field has been particularly rapid recently in the United States.
A wide range of experimentation is being conducted in the United States, using Web technologies from PDAs to high-performance graphics on ultra-wide-area networks, testing technologies from ultra-large-scale numerical processors to commercial services. The results of this survey underscored for the Wide-area Distributed Computing Working Group how seriously Japan has fallen behind in this area of research.
(2) Researchers seconded to JIPDEC from Hitachi
Hitachi's researchers are veterans of over 10 years' work in research and development of that company's supercomputers and massively parallel computers, and continue to work on the leading edge of R&D in parallelizing compiler technology, including commercialization. From 1997 to 1999, Hitachi conducted research and development in parallelizing software for multiprocessors, under contract from the New Information Processing Development Corporation*. In the course of this work, research in instruction-level parallelization for microprocessors and elemental technologies for parallelization for use in boosting effective performance of the hardware in multiprocessor systems whose constituent elements are microprocessors. After this contract research was completed, the company continued to pursue research and development on the basis of the results of the contract research project.
The details of that contract research project are as follows. In multigrain parallelizing compiler research, Hitachi conducted R&D in interprocedural parallelization technology, which is a kind of parallelization technology that focuses on loops that include subroutine cores. The company also developed the Whole Program Parallelizer (WPP), an interprocedural parallelizing compiler that outputs parallelization results as source programs written to industry standard OpenMP specifications. This technology was exhibited at Supercomputing '99 as part of the contract research project. WPP includes a prototype (client/server) of a parallelization visualization technology that renders various information required by the user, such as program structure and factors preventing parallelization, in an easily understood format.
The status of research and development in various elemental technologies in multigrain parallelization is as follows.
Looking first at data-sensitive analysis technology, Hitachi achieved high-speed, high-precision array data flow by combining two technologies based on interprocedural analysis. The first technology expresses data reference domains using a rectangular domain capable of low-precision but high-speed calculation; the second is an unequal format used when high-precision but low-speed linear calculation is necessary. Hitachi also conducted research and development of a technology that where necessary combined cloning of procedures with propagation of constants between procedures, thus expanding the scope of application of the propagated constant. The company incorporated all of these technologies in WPP and continues to examine other technologies required to boost analytical precision further.
A number of automatic data distribution technologies were also developed. For distributed-memory parallel computers, Hitachi examined a technology that distributes array data across procedures, through multiple array dimensions and across multiple loops. For DSM computers, which are expected to achieve explosive market growth in the near future, Hitachi examined how DSM could be optimized and presented its findings at an academic conference. Hitachi also proposed, tested and evaluated an automatic data distribution method that enabled optimal data distribution by controlling DSM's unique fast-touch data distribution method through the compiler.
In platform-insensitive parallelization technologies, Hitachi equipped WPP with a function that outputs parallelization results as source programs under OpenMP specifications. The company also prepared the first draft of an extended specification for OpenMP, in view of extensions to data distribution, and tested the specification on NAS Parallel Benchmark, an industry standard parallelization benchmark.
(3) Researchers seconded to JIPDEC from Fujitsu
The researchers seconded from Fujitsu are world leaders in parallel extraction technology. From the automatic vectorizing compiler developed for the VP supercompiler series in 1984 to the automatic vectorizing compiler developed for the modern VPP supercomputer series and the automatic parallelizing compiler developed for the parallel scalar server, these researchers are acknowledged experts on the leading edge of automatic vectorization and parallelization technology.
In automatic data distribution technology, from a parallelizing compiler developed for the VPP series of distributed parallel supercomputers in 1993 to the modern HPF compiler, Fujitsu's researchers have developed a number of parallelizing technologies for distributed parallel machines, demonstrating a wealth of expertise in the field.
In speculative running, a method of speculative running at the task level was proposed which uses selective prediction to predict the actual values, between tasks in which the dependency relationship with the data is a true dependency. The researchers seconded from Fujitsu bring this valuable experience to the project (1) (2) (3).
In parallel description languages, Fujitsu designed specifications for a parallel description language (the VPP Fortran specifications) for use in the VPP series of distributed parallel supercomputers and developed a processing system. Also, in SC99 and 2000RWC, the company proposed extended specifications for OpenMP for application to be distributed parallel computers, evaluated their performance on the VPP series and confirmed improvement in performance.
(1) Possibility of data prediction for speculative running
Yasushi Iwata, Akira Anzato, Masaki Arai, Toshihiro Ozawa, Ysunori Kimura
Computer Architecture Research Society of the Information Processing Science Academy, August 5, 1998
(2) Evaluation and examination of selective prediction using metatools
Yasushi Iwata, Kazuhiro Suziki, Akira Anzato, Ysunori Kimura
Computer Architecture Research Society of the Information Processing Science Academy, 1999
(3) Basic examination of parallel running of control flows for value prediction
Akira Anzato, Kazuhiro Suziki, Yoshiro Ikeda, Ysunori Kimura
59th International Conference of the Information Processing Science Academy, 1999
In parallelizing tuning technology, Fujitsu developed tuning tool technologies possessing a dynamic analytical function for analyzing parallels and a visualization function, both for the VPP supercomputer series and parallel scalar server. These accomplishments indicate the high level of expertise of the researchers seconded to JIPDEC by Fujitsu.
2-2. Equipment Possessed by the Project Team for R&D Purposes
(1) Development of APC technology
|
Model and quantity
|
Description
|
| FujitsuGP7000Fmodel1000 |
SMP machine consisting of 16 SPARC processors, to be used for development of automatic multigrain parallelizing technology
|
| Fujitsu S-4/20H *6 |
SPARC processor workstations, to be used by researchers for program development |
| Fujitsu S-7/400 *4 |
SPARC processor workstations, to be used by researchers for program development |
| SGI Origin2000 |
DSM machine consisting of 32 MIPS10000 processors, to be used for research and development of automatic multigrain parallelizing technology
|
| HP9000 C360 *2 |
PA-RISC processor workstations, to be used by researchers for program development |
| HP9000 C180 *2 |
PA-RISC processor workstations, to be used by researchers for program development |
(2) Development of parallelizing compiler performance evaluation technology
|
Model and quantity
|
Description
|
| FujitsuGP7000Fmodel1000 |
SMP machine consisting of 16 SPARC processors, to be used for development of parallelizing compiler performance evaluation technology
|
| Fujitsu S-4/20H *6 |
SPARC processor workstations, to be used by researchers for program development
|
| Fujitsu S-7/400 *4 |
SPARC processor workstations, to be used by researchers for program development
|
| SGI Origin2000 |
DSM machine consisting of 32 MIPS10000 processors, to be used for research and development of parallelizing compiler performance evaluation technology
|
| HP9000 C360 *2 |
PA-RISC processor workstations, to be used by researchers for program development
|
| HP9000 C180 *2 |
PA-RISC processor workstations, to be used by researchers for program development
|
2-3. Impact of Research and Development Results on Industry
(Commercialization)
The purpose of this R&D project is to establish a compiler technology that will double effective performance of high-performance multiprocessors and propose ways of incorporating the technology into system architectures. Commercialization is expected to proceed as follows.
1) Adoption in next-generation parallelizing compilers
The results of this project will be adopted and commercialized in parallelizing software systems that elicit improved performance from high-performance computers and next-generation PCs (parallelizing compilers for next-generation multiprocessors owned by end users.
2) Adoption in next-generation multiprocessor systems
The demand for hardware systems that link with software technology to achieve a higher level of performance is reflected in the high-performance multiprocessors (including SCMs) at each manufacturer.
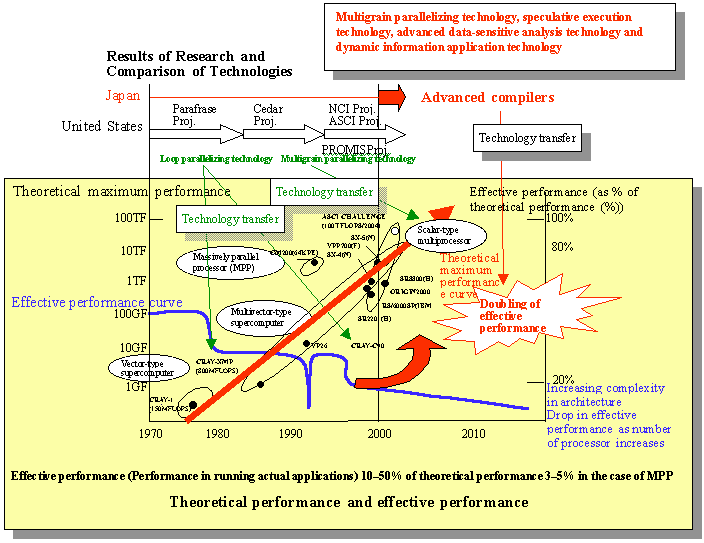
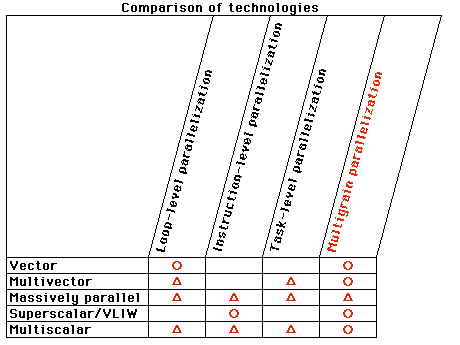
(Impact on industry)
The impact of this research and development project will be to raise the effective performance of multiprocessor systems, thereby improving their cost-performance, so that a significant boost in processing speed can be achieved in an HPC with the same number of processors, ultimately resulting in improved competitiveness for Japan's computer industry. It will also strengthen Japan's competitiveness in a wide swath of other industries and fields of research. These include handheld terminals, information appliances, PCs, workstations, HPCs and other IT products and extend to many other industries where advanced information processing is required, such as automobiles, aerospace, bio-informatics, medicine, the environment, financial engineering and electronic commerce (EC).
This project will also reinforce the technological capabilities of Japan's software industry. Its impact includes not only the development of the IT industry, improved global competitiveness and job creation, but also the development of a new platform technology that will underpin new forms of energy, safe use of nuclear energy, stable energy supply after the electrical power industry is deregulated, automobile and aerospace design, ULSI design automation, power generating plant and steel mill control systems, advanced IP robots, information appliances, energy-saving technologies and many other fields. The results of the project will promote science and technology in the 21st century and contribute to the growth of new businesses. In short, the impact of this project will be immense.
In advanced fields such as biotechnology, device engineering and environmental technology, computer simulations play a crucial role. This research and development project will double the effective performance of such simulations, enabling twice* as much simulation output to be generated in the same processing time. The technologies resulting from this project will provide indispensable support to the next generation of computer science.
In conclusion, the impact of this project will be extraordinarily high, not only in IT but in a wide range of industries.
(*) For example, if the theoretical maximum performance of parallelizing computers five years from now is 100 times its present level, the doubling effect of this research and development project will increase effective performance 200 times. Without the results of this R&D effort, effective performance will only have improved 100 times.
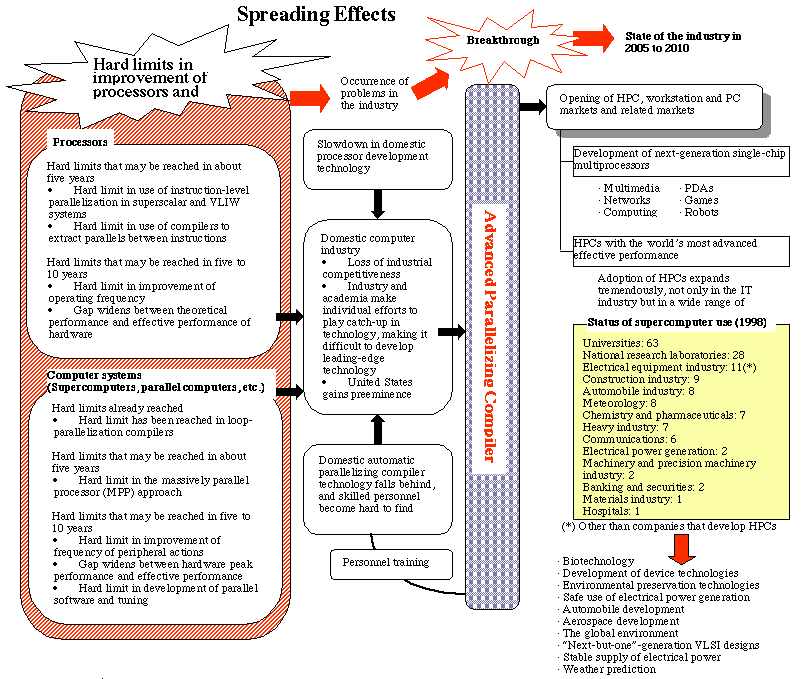
(Application results and commercialization scenarios)
This project will hold down infrastructure costs by proceeding with development on the basis of existing compilers already in the possession of the participating companies and universities. As a result, the project team will be able to focus on developing new technology. Because the APC technology will be built on existing compiler platforms, quantitative evaluation can be carried out on programs at the practical level. Companies can easily decide whether and when to commercialize the technology and take steps to shorten lead time to commercialization.
Each company will actively apply the technologies created to the development of compilers and other parallelizing software systems, as well as high-performance computer products.
Hitachi uses SMPs consisting of arrays of microprocessors as calculation nodes. The company already markets a product consisting of parallel computers connecting such nodes through a high-speed network, and has garnered sales of 30 billion yen worldwide. This parallelizing compiler for use in parallel computers was developed entirely by Hitachi. Hitachi considers the results of the APC research and development project to be essential, as they will boost the performance of parallel computers, and wishes to bring the project, including portions already in progress, to commercialization as soon as possible.
Fujitsu has brought to market distributed-memory parallel supercomputers and shared-memory parallel computers that use RISC processors, whose parallelizing language and parallelizing compiler were developed in-house. Fujitsu considers the results of the APC research and development project to be essential, as they will boost the performance of parallel computers, and wishes to bring the project, including portions already in progress, to commercialization as soon as possible.
(Commercialization time-frame)
Two years from completion of R&D
|
|
|