|
Name of University
|
The University of Electro-Communications |
| Representative |
Makoto Kajitani, University President |
| Location: |
1-5-1 Chofugaoka, Chofu-city, Tokyo |
| Contact |
Hiroki Honda, Associate Professor
|
|
Postgraduate Research Institute of Information System Studies |
|
TEL 0424-43-5641
|
|
FAX 0424-43-8923
|
|
e-mail honda@acm.org
|
[Body]
Title of research and development project:
Advanced Parallelizing Compiler Technology
Research and development theme:
Development of Technologies for the Evaluation of Parallelizing Compiler Performance
[1] Details and Targets of Research and Capability of Performing Research and Development
|
1. Details and Targets of Proposed Research and Development
1-1. Overview of Research and Development
This project will establish technologies that provide impartial evaluation of the performance of APC systems, such as the automatic multigrain parallelizing technology that performs parallel processing in SMP systems. Specifically, a format that uses benchmarks to evaluate performance on actual systems will be adopted, so benchmark programs, execution rules and evaluation indices will be selected to ensure fair and objective performance evaluation. Because APC technology involves the integration of fairly independent individual functions, individual functions will be evaluated by developing benchmarks from kernels and compact applications, while general performance evaluation will be provided by development of benchmarks from full-scale applications.
1-2. Details and Targets of Research and Development
One of the most widely adopted approaches to evaluation of the performance of computer systems consists of measuring the execution time of a benchmark program on an actual machine. Unfortunately none of the benchmarks now available specifically focus on evaluating the performance of parallelizing compilers, so evaluation of parallelizing compiler performance has to be conducted using benchmarks that evaluate the performance of the CPU, the entire system, or parts thereof.
Although the use of such benchmarks to measure the performance of compilers is not inappropriate in itself, the criteria by which benchmarks are selected are still vague. Consequently, the information published in performance evaluation reports on the rules of execution and the setting of conditions is never sufficient.
In some cases it is not possible to reach a consensus on which individual functions contribute most to performance. For example, in the SWIM program of the SPEC CPU95fp benchmark, simple loop parallelization appears to achieve something close to hardware peak performance, and so is of little use in evaluating individual functions of the parallelizing compiler. In contrast, the FPPPP program of the SPEC CPU95fp benchmark indicates that little or no improvement in performance is possible no matter how the parallelizing compiler is optimized, due to hardware constraints. This benchmark delivers completely different results but is equally useless in evaluating parallelizing compiler performance.
This project will conduct research and development in benchmarks for evaluation of the performance of APC systems such as the automatic multigrain parallelizing compilers used in SMP systems. This effort consists of 1) preparation and selection of benchmark programs, 2) setting of run rules and 3) setting of measurement indices. The final targets are as follows. By using these benchmarks to evaluate R&D item 1), this project aims to establish technology that can provide objective evaluation of the performance of parallelizing compilers. Research and development will broadly focus on the following two methods.
(1) Development of technologies for the evaluation of individual functions
This project will conduct research and development in methods of evaluation of the individual functions held by compilers. Programs that test for the grains used in automatic multigrain parallelization and for the presence and effect of individual functions, such as data-dependent analysis technology, speculative running technology and automatic data distribution technology are prepared as kernel benchmark programs (including items other than loops). Existing benchmark programs and parts of applications are selected as compact application benchmark programs.
In conducting R&D into these methods, the following items will be examined with respect to establishing important rules of running, to ensure that the performance evaluation is carried out in an objective and fair manner.
- Extent and levels of authorization for manual insertion of compiler directives into the source code and changes to the source code
- Methods of setting compiler options (types and degrees of optimization/parallelization): Limits on the number of options that can be set, whether or not optimal compiler options can be set individually for each program
- Running environment: data size, number of processors, operating system (system tuning parameters such as single-user/multi-user, stopping/starting of daemons and page size)
Measurement indices for performance evaluation will not merely measure running time under specific environments. The types of indices needed will be examined and clarified. For example, code scalability indices may be generated, indicating how performance changes when programs are executed with different numbers of processors, or performance portability indices may be generated, indicating how performance changes when programs are executed on different systems.
This research and development project must solve the following problems.
- The fairness and reasonableness of the benchmark programs must be recognized with respect to who developed them, who selected them and how they were collected.
- It must be easily verifiable that the results of running the program are reasonable and that margins of error fall within acceptable bounds.
- Additions other than the source code of the benchmark program (program running results, functions for self-checking of running results, data sets, documents, methods of calculation of performance indices) should be provided in an easy-to-use application software package form.
If actual application programs are to be used as benchmark programs, the following problems must be solved.
- Programs that are widely used in the market may be difficult to obtain for free. Publication and distribution may also not be allowed for security or secrecy reasons.
- With large-scale application programs, upgrades and the like tend to raise maintenance costs.
- A great deal of labor may be required to port an application from one computer to another.
- To enable the benchmark program to be used on many computers, the programming language used to describe it must be a standard language.
<Final target>
To evaluate individual functions of parallelizing compilers (testing for presence of functions and the capabilities of individual functions), kernel benchmark programs are prepared, or parts are selected from existing benchmark programs and applications as compact application programs, taking indices such as code scalability indices and performance portability indices into consideration.
(2) Development of methods for evaluation of general performance
This project will conduct research and development in methods of evaluating the general performance of compilers independently of the configuration or performance of the hardware. Existing benchmark programs and application programs are selected as full-scale application benchmark programs, and parts of full-scale applications and compact applications that model the actions of full-scale applications are also selected. In selecting these programs, the present technological level of the compiler is considered, and the target in use at that time for development of compiler technology is stated and selected for use in promoting technological development.
In conducting R&D into these methods, the following items will be examined with respect to establishing important rules of execution, to ensure that the performance evaluation is carried out in an objective and fair manner.
Extent and levels of authorization for manual insertion of compiler directives into the source code and changes to the source code
- Methods of setting compiler options (types and degrees of optimization/parallelization): Limits on the number of options that can be set, whether or not optimal compiler options can be set individually for each program
- Running environment: data size, number of processors, operating system (system tuning parameters such as single-user/multi-user, stopping/starting of daemons and page size)
Measurement indices for performance evaluation will not merely measure execution time under specific environments. The types of indices needed will be examined and clarified. For example, code scalability indices may be generated, indicating how performance changes when programs are executed with different numbers of processors, or performance portability indices may be generated, indicating how performance changes when programs are executed on different systems.
This research and development project must solve the following problems.
- The fairness and reasonableness of the benchmark programs must be recognized with respect to who developed them, who selected them and how they were collected.
- It must be easily verifiable that the results of running the program are reasonable and that margins of error fall within acceptable bounds.
- Additions other than the source code of the benchmark program (program execution results, functions for self-checking of execution results, data sets, documents, methods of calculation of performance indices) should be provided in an easy-to-use application software package form.
If actual application programs are to be used as benchmark programs, the following problems must be solved.
- Programs that are widely used in the market may be difficult to obtain for free. Publication and distribution may also not be allowed for security or secrecy reasons.
- With large-scale application programs, upgrades and the like tend to raise maintenance costs.
- A great deal of labor may be required to port an application from one computer to another.
- If a benchmark program is used on many computers, the programming language used to describe it must be a standard language.
<Final target>
The final target for this aspect of the project is to select existing benchmark programs and application programs for use as full-scale application benchmark programs, taking indices such as code scalability indices and performance portability indices into consideration.
1-3. Research and Development Plan
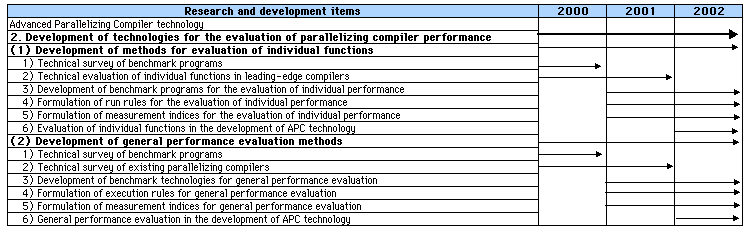
2. Research and Development Capability
2-1. Research and Development Track Record
The Honda Laboratory is established in the Parallel Processing Course in the Department of Information Processing Systems Research, The University of Electro-Communications. This laboratory has pioneered important research in parallel processing configuration methods, parallel running methods and automatic parallelizing compiler systems. Over the past three years, the Laboratory has published four papers. In the course of these efforts, the Laboratory has conducted extensive performance evaluation using the systems developed and is thus eminently qualified to carry out the development of technologies for the evaluation of parallelizing compiler performance.
1) "A One-to-one Synchronous Configuration for Fine-grain Parallel Processing in Multiprocessor Systems," (Hayakawa, Honda), Journal of the Information Processing Society, Vol. 38, No. 8, pp1630-1637,1997
2) "Proposal and Performance Evaluation for an RCBQ Synchronous Configuration and Related Synchronous Method," (Hayakawa, Honda), Journal of the Information Processing Society, Vol. 39, No. 6, pp1655-1663,1998
3) "Performance Measurements on Sandglass-type Parallelization of Doacross Loops (Takabatake, Honda, Ohsawa, Yuba), Journal of the Information Processing Society, Vol. 40, No. 5, pp2037-2044,1999
4) Performance Measurements on Sandglass-Type Parallelization of Doacross Loops (M.Takabatake, H.Honda, T.Yuba), Proc. of 7th Int. Conf. High-Performance Computing and Networking (Lecture Notes in Computer Science 1993, Springer) pp663-672, 1999.
2-2. Holding Status of Research and Development Equipment
|
Type of Equipment
|
Details
|
|
Workstations
|
Sun Ultra10
|
|
Parallel processing systems
|
Sun Enterprise 450
|
2-3. Effects on Industry of the Results of Research and Development
The parallelizing compiler plays a vital role in achieving highly efficient parallel processing in parallel processing systems. By enabling fair and impartial evaluation of the parallelizing compiler resulting from this research and development project, the development of this evaluation technology will promote commercialization of the fruits of this research and stimulate growth in industries related to parallel processing systems.
[2] Plan for FY 2000 (First Year)
|
1. Details of FY 2000 Research and Development
1-1. Technological trends
Benchmarks (also called benchmark suites) are generally defined as benchmark programs plus the run rules by which they operate. In most cases benchmark programs are made available as source code.
Benchmark programs in use today can be broadly classified into three types as follows.
Kernel benchmark programs:
Vector calculation machines and initial parallel calculation machines are used to parallelize a single loop. Their performance is evaluated using kernel benchmark programs, which are incorporated into the portion of the program, focusing on loops that consume most of the run time. Principal examples of this type of benchmark are Livermore Loops, LINPACK and NAS kernels. Even today, these kernel benchmarks are frequently used in the evaluation of single-loop optimization and parallelization.
Full-scale application benchmark programs:
In many of today's parallel computers, however, parallelization is conducted across entire programs. It is now clear that kernel-type benchmarks are wholly inadequate to evaluate the performance of parallel computers in executing applications. In particular, performance in transfer of data required when the optimal data allocation differs between kernels cannot be evaluated within a single kernel. In such cases it has become common to use a full-scale application program as the benchmark program.
Compact application benchmark programs:
Despite the advantages listed above, the use of full-scale application programs as benchmark programs is fraught with the problems of copyright and the sheer size of the programs. An efficient solution is to extract several kernels with desired attributes from such full-scale applications to create a compact application, a program consisting of a few thousand lines at most. A compact application enables a programmer to evaluate performance with proficiency approaching that obtained using a full-scale application, and provides a way of focusing on particular aspects of the system, such as data communication performance and synchronizing overhead.
When using benchmark programs to measure performance, run rules are established to ensure that the results are fair and impartial. Generally information is published in the performance evaluation reports regarding the settings used to perform measurement.
- Tolerance for manual changes to the source code
- Tolerance for manual insertion of compiler directives in the source code
- Method of setting compiler options (types and extent of optimization/parallelization)
- Limits on the number of options that can be set
- Availability of a function to set optimum compiler options for each program
- Running environment
- Data size
- Number of processes
- Operating system environment (system tuning parameters such as single user/multiple users, stopping/starting of daemons and page size)
A number of indices are used to display the results of performance evaluation. The most common of these is program run time, but throughput may also be used. Although a simple display of time may be adopted, number of instructions run per unit of time may also be used as a means of displaying a comparison with the performance of a criterion computer. The following is a sample of some of the most common conventional benchmarks used performance evaluation in compiler-related research.
e. Perfect Benchmarks
Perfect Benchmarks (an acronym for "PERFormance Evaluation for Cost-effective Transformations) is a benchmark for technical and scientific calculations for high-performance supercomputing. Perfect Benchmarks is the product of development work between the University of Illinois' Center for Supercomputing Research and Development (CSRD) and a number of collaborating research facilities and private corporations. Begun in 1988, the finished benchmark was published in October 1993.
Perfect Benchmarks' benchmark programs consist of 13 application programs written in Fortran77. These programs were provided by the CSRD, IBM Kingston Laboratories, NASA Ames Research Center, Princeton University, Cray Research and California Institute of Technology.
Performance is measured by comparing CPU time to run each program with wall-clock time. The result is used to calculate a value in millions of floating point operations per second, or MFLOPS.
This performance is measured in two ways. In the original (baseline) run, each program must be run as is, so only the absolute minimum manual changes in the code necessary to compile and run the program are permitted. Optimization using compilers and preprocessors is permitted, however.
In the second phase, step-by-step manual optimization of the source program is carried out. During this process, it is essential that an optimization diary be carefully recorded and reported, indicating what type of optimization is carried out, what improvement in performance was achieved and what kind of effort was required.
In measuring performance, the running environment for the benchmark programs consists of use by a single user. No daemons are used other than daemons absolutely essential for system operation.
To judge whether the results of the program run are correct, the values obtained as a result of running are compared with a previously prepared list of expected run results. A function is provided for examining whether the values obtained are within tolerance.
Perfect Benchmarks is a set of applications assembled in part by CSRD, an acknowledged leader in parallelizing compiler research, and is widely used as a benchmark program for evaluation purposes in the research work of researchers associated with CSRD. For these reasons the project team considers Perfect Benchmarks to be an appropriate set of benchmarks for use in evaluating the performance of automatic parallelizing compilers.
f. SPEChpc96
The Standard Performance Evaluation Corporation/High Performance Group (SPEC/HPG) began work on the development of SPEChpc96 in January 1994 and announced it in 1995 at the Supercomputing '95 trade exhibition. The key members of SPEC/HPG were the members of SPEC and a group of Perfect Benchmarks researchers. To these were later added researchers from the Parkbench, Seismic Benchmarks and other benchmark projects, as well as members from private industry and various research organizations. SPEChpc96 is a benchmark produced for the purpose of evaluating the performance of high-end parallel and distributed computers, and is capable of providing performance evaluation indices beyond simple measures of peak performance.
The benchmark programs of which SPEChpc96 is composed are numerical calculation programs used for processing on high-end computers in various industries and fields of research.
The benchmark programs in the current version of SPEChpc96 consist of three application programs written in Fortran and C. These programs are SPECseis96 and SPECchem96, which were part of the suite when SPEChpc96 was announced, and SPECclimate, which was added in 1998.
To measure performance, the time taken to run the benchmark program is measured. A value of 86,400 seconds (one day) for this run time is used as the SPEChpc96 benchmark index. At first glance it is easy to mistake this index as a simple indication of throughput, but it is important to note that it is in fact an indication of turnaround time.
When measuring performance, the person running the benchmark program can specify the state in which the system is run, but the state in which the measurement was carried out must be published.
When running the benchmark program, optimization of code is permitted only within a limited range. Permitted types of optimization are those within the capability of a general user operating a high-performance computer. These include manual rewriting of code, setting of compiler options (flags) and use of compiler directives (or language extensions). Any optimizations made must be published. Unlike SPEC CPU (see below), SPEChpc96 does not support measurement of baseline runs.
SPEChpc96 can run both serial and parallel programs, so this benchmark can be used to evaluate scalability from serial to parallel application. It can also be used to compare the running times of parallel programs with those of serial programs compiled on a parallelizing compiler, which is expected to be useful in evaluating compiler performance.
g. SPEC CPU2000
Announced in December 1999, SPEC CPU2000 was developed by SPEC/OSG as a successor to SPEC CPU89, SPEC CPU92 and SPEC CPU95. SPEC CPU95 is today one of the most commonly used benchmarks for commercial machines (processors). Key changes in the upgrade from SPEC CPU95 to SPEC CPU2000 are as follows.
- The run time for each benchmark program was made longer.
Due to progress in the speed of computer systems, benchmark programs ended too quickly under SPEC CPU95. SPEC CPU2000 was fixed to make run time sufficiently long even when running on newer systems.
- Problem sizes in each benchmark programs were made larger.
SPEC CPU95 had failed to reflect the recent increase in size and complexity of actual application programs. The problem sizes in SPEC CPU2000 were therefore increased.
- The total number of benchmark programs was increased.
SPEC CPU2000 was designed to evaluate overall performance, including the processor, memory and compiler. It cannot be used to evaluate performance of I/O, networks or graphics.
Whereas CINT2000 consisted of 12 application programs, SPEC CPU2000 included 14 application programs. This wide range of programs included in the benchmark is a unique feature of SPEC CPU2000.
These application programs were selected in consideration of the following factors.
- Program portability among different hardware and operating systems is high.
- The programs do not involve a great deal of I/O processing.
- They do not involve networking or graphics.
- They can operate on 256MB of main RAM without swapping.
- Run time spent on portions other than the code supplied by SPEC is 5% or less of total run time.
Generally speaking, the performance of computer systems tends to use system speed (turnaround time) and throughput. SPEC CPU2000 also measures these items, displaying the results as "none-rate (speed)" and "rate (throughput)."
When a parallelizing compiler is used to run one program on several compilers, the results appear as "none-rate." SPEC CPU2000 clearly indicates that the results were obtained from parallel processing.
SPEC CPU2000 has highly detailed rules on the compiler options (optimization flags) that can be set when using this program to compile source code. Two ways of evaluating performance are provided, using two different indices to display results, depending on the means of setting options. The first of these is the base index. In the base index, four compiler options can be set optionally for measurement, but all benchmark programs must be set to the same options. This index is intended for users who are not interested in optimization but simply wish to run the compiler as is. It is a required index for measurement result reports. The second index is the no-base (peak, aggressive compilation) index. The no-base index sets no limits on the number of compiler options that can be set, and different options can be set for different programs. This index is intended for users who wish to perform aggressive optimization on their programs, and is optional for inclusion in measurement result reports.
SPEC CPU is a widely used benchmark, applied not only in the parallel processing field but in general computing, workstations and PCs as well. Performance evaluations of parallelizing compilers conducted on SPEC CPU are fairly easy for general users to compare and understand.
h. NAS Parallel Benchmarks (NPB)
NPB is a benchmark provided by the Numerical Aerospace Simulation (NAS) program of NASA Ames Research Center to evaluate the performance of parallel supercomputers. This benchmark was created for the purpose of evaluating the performance of distributed-memory massively parallel computers in solving computational fluid dynamics (CFD) problems, as part of NASA's project to develop an aerospace vehicle for the 21st century.
NPB 1.0 was developed in 1991. NPB's unique feature as a benchmark is that only the specifications of the problem to be solved are stipulated; data structure, algorithms and programming are performed by the person performing the implementation. NPB's benchmark programs simulate the calculations and data transfer performed by CFD programs. Accordingly, NPB consists of three virtual applications that reproduce the data transfer and calculation within the CFD code and in the five parallel kernels at the core of five calculation methods used in the CFD program.
NPB is strictly focused on a single application program. It is used to perform detailed evaluation of the processing performance of each portion of that application.
i. PARKBENCH
PARallel Kernels and BENCHmarks (PARKBENCH) developed as a comprehensive parallel processing benchmark. Work on the project began when the PARKBENCH Committee was formed in 1992, and the benchmark was announced in 1993. Originally designed to evaluate the performance of distributed-memory machines, PARKBENCH used benchmark programs described in Fortran77 and PVM. In the current version, MPI programs are also included.
PARKBENCH consists of 10 low-level benchmark programs, used to evaluate basic system performance; seven kernel benchmark programs, including NPB's FT/MG; and four compact applications, including NPB-CFD's LU/ST/BT).
An HPF compiler benchmark is appended to PARKBENCH. This compiler benchmark, which comprises 10 kernel benchmarks, is used to evaluate the running of special syntax elements in HPF such as for all and independent.
PARKBENCH uses three types of benchmark programs to evaluate system performance. Its distinguishing feature is its use of an anatomical approach to performance evaluation.
1-2. FY 2000 Details of Research and Development
In FY 2000, the following research and development activities are to be carried out with respect to the existing benchmarks described in 1-1.
(1) Development of methods of evaluation of individual functions
One of the most widely adopted approaches to evaluation of the performance of computer systems consists of measuring the run time of a benchmark program on an actual machine. Unfortunately none of the benchmarks now available specifically focus on evaluating the performance of parallelizing compilers, so evaluation of parallelizing compiler performance has to be conducted using benchmarks that evaluate the performance of the CPU, the entire system, or parts thereof. Although the use of such benchmarks to measure the performance of compilers is not inappropriate in itself, the criteria by which benchmarks are selected are still vague. Consequently, the information published in performance evaluation reports on the run rules and the setting of conditions is never sufficient. Moreover, the contributions of individual functions to the performance of the compiler cannot always be readily identified.
A survey will be conducted of the various benchmarks currently diverted for the evaluation of performance in individual functions of parallelizing compilers. Through this survey, guidelines will be clarified for 1) selection of kernel and compact-application benchmark programs, 2) setting of run rules and 3) setting of measurement indices in evaluating the performance of individual functions of parallelizing compilers. Finally, a survey will be conducted of the individual functions of existing parallelizing compilers to clarify the current state of the technology. This effort will clarify the orientation of development to ensure that the resulting benchmark is an appropriate target for technological development and will promote the development of related technology.
Technology issues in ensuring that the benchmark is appropriate for evaluating the performance of the individual functions
|
Technology items
|
Conventional technologies
|
Key issues
|
Technology that clarifies the relationship with the program
|
Failed to clarify which portions of the program the individual functions were effective in
|
Technology to indicate qualitatively and quantitatively which individual functions are effective in which portions of the program
|
|
Technology that clarifies the relationship with other individual functions
|
Failed to clarify the relationship with other individual functions
|
Technology that conducts evaluation with minimum impact on other individual functions and indicates what impact it has on other individual functions
|
|
Technology that clarifies the relationship with the hardware
|
Failed to clarify the degree of sensitivity to the hardware
|
Technology that conducts evaluation of hardware-insensitive individual functions with minimum impact on hardware and indicates what impact it has on the hardware
|
(2) Development of general performance evaluation methods
One of the most widely adopted approaches to evaluation of the performance of computer systems consists of measuring the run time of a benchmark program on an actual machine. Unfortunately none of the benchmarks now available specifically focus on evaluating the performance of parallelizing compilers, so evaluation of parallelizing compiler performance has to be conducted using benchmarks that evaluate the performance of the CPU, the entire system, or parts thereof. Although the use of such benchmarks to measure the performance of compilers is not inappropriate in itself, the criteria by which benchmarks are selected are still vague. Consequently, the information published in performance evaluation reports on the run rules and the setting of conditions is never sufficient. Moreover, the contributions of individual functions to the performance of the compiler cannot always be readily identified.
A survey will be conducted of the various benchmarks currently diverted for the evaluation of general performance of parallelizing compilers. Through this survey, guidelines will be clarified for 1) selection of compact-application and full-scale-application benchmark programs, 2) setting of run rules and 3) setting of measurement indices in evaluating the general performance of parallelizing compilers. Finally, a survey will be conducted of existing parallelizing compilers to clarify the current state of the technology. This effort will clarify the orientation of development to ensure that the resulting benchmark is an appropriate target for technological development and will promote the development of related technology.
Technology issues in ensuring that the benchmark is appropriate for evaluating general performance
|
Technology items
|
Conventional technologies
|
Key issues
|
Technology that performs hardware-insensitive performance evaluation
|
Performance evaluation includes the hardware
|
Technology that clearly distinguishes hardware-dependent portions from hardware-independent portions and uses actual applications to evaluate the performance of the compiler
|
|
Technology for fair and impartial comparison of compiler performance
|
Benchmark targets only specific programs
|
Technology that embraces program portions in which the individual functions of various compilers are expected to have an effect
|
3 Research and Development Implementation Structure
|
1. Research Organization and Management System
1-1. Officers responsible for Research Implementation
Officer Responsible for research Implementation: Harunari Nagasue Director of Secretariat, The University of Electro-Communications
(Officer in charge: Makio Kadota, Chief of Research Cooperation Section, Administrative Department, The University of Electro-Communications)
Accounting Manager: Tetsu Iwamoto, Chief of Bookkeeping Section, Accounting Department, The University of Electro-Communications
1-2. Organization Chart
University President Officer Responsible for Research Implementation Accounting Department Bookkeeping Division Head of Postgraduate Research Institute of Information System Studies Researchers

1-3. Research Locations
The Honda Laboratory, Parallelizing Processing Studies Class of Postgraduate Research Institute of Information System Studies, The University of Electro-Communications
IS Block 5th Floor, 1-5-1 Chofugaoka, Chofu-city, Tokyo 50m2
2. Names of Researchers
|
Name
|
Location and post
|
Key research history and achievements
|
|
Hiroki Honda (Doctor of Engineering)
|
Associate Professor, specialized in Information Networking Studies of Postgraduate Research Institute of Information System Studies, The University of Electro-Communications
|
- "Proposal and Performance Evaluation for an RCBQ Synchronous Configuration and Related Synchronous Method," (Hayakawa, Honda), Journal of the Information Processing Society, Vol. 39, No. 6, pp1655-1663,1998
- "Performance Measurements on Sandglass-type Parallelization of Doacross Loops (Takabatake, Honda, Ohsawa, Yuba), Journal of the Information Processing Society, Vol. 40, No. 5, pp2037-2044, 1999
- Performance Measuremets on Sandglass-type Parallelization of doacross Loops (M.Takabatake, H.Honda, T. Yuba) Prod. Of 7th Int. conf. High-Performance Computing and Networking (Lecture Notes in Computer Science 1593, Springer), pp.663-672, 1995
Years of research experience: 17 years
|