|
[Subcontract Proposal]
Proposal for Advanced Parallelizing Compiler Technology
Research and development theme
`Development of technologies for the evaluation of parallelizing compiler performance'
|
University
|
The University of Electro-Communications
|
|
Tokyo Industrial University Director of Secretariat, Takashi Watanabe
|
| Location |
2-12-1 Ohokayama, Meguro-ku, Tokyo (152-8550)
|
| Contact |
Kento Aida, Lecturer |
|
Intelligence System Studies of Postgraduate Comprehensive Research Institute of Science and Engineering, The University of Electro-Communications
|
|
TEL (045) 924-5168
|
|
e-mail aida@dis.titech.ac.jp
|
|
If the contact address is different from the address given above
|
|
(Contact Location)
|
|
4259 Nagatsudamachi, Midori-ku, Yokohama-city, Kanagawa (226-8502)
|
|
TEL (045) 924-5168
|
|
e-mail aida@dis.titech.ac.jp
|
[Body]
Name of research and development project:
Advanced Parallelizing Compiler Technology
Research and development theme:
Technologies for the Evaluation of Parallelizing Compiler Performance
[1] Details and Targets of Research and Capability of Performing Research and Development
|
1. Details and Targets of Proposed Research and Development
1-1. Overview of Research and Development
The theme of this research and development project is "development of technologies for the evaluation of parallelizing compiler performance," which means that its objective is to establish performance evaluation technologies that support the development of parallelizing compiler technologies. Research will be conducted in methods for the evaluation of the performance of parallelizing compilers, and a suite of benchmark programs will be developed for use in conjunction with these technologies.
1-2. Details and Targets of Research and Development
To improve the performance of parallelizing compilers, the developed parallelizing (optimizing) technologies must be evaluated in a way that is both detailed and consistent with other such technologies, to provide essential feedback of evaluation results to the development process. The most common means to achieve these objectives is to evaluate the performance of parallelizing compilers using benchmark programs.
The purpose of this project is to establish performance evaluation methods to support the development of parallelizing compiler technology. Specifically, research will be conducted in 1) methods of evaluating each of the individual parallelization technologies in the parallelizing compiler and 2) methods of evaluating performance using measures that provide uniform evaluation among several parallelizing compilers. Additionally, a suite of benchmark programs will be developed to achieve this goal. The developed suite of benchmark programs will include small-scale programs, used to evaluate individual parallelization (optimization) functions of parallelizing compilers, and large-scale programs, used to provide uniform evaluation of overall parallelization performance.
Research and development will be carried out according to the following procedures.
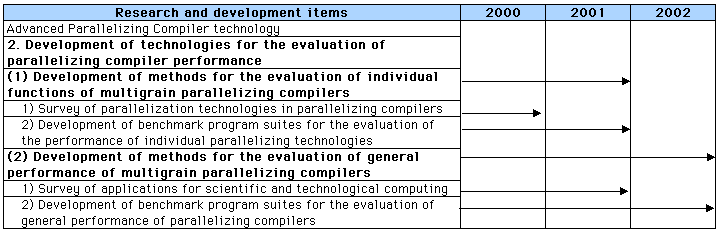
(1) Development of technologies to evaluate the performance of individual parallelization technologies
1) A survey will be conducted of existing parallelizing compiler technologies developed for research or commercial purposes, such as loop parallelizing compilers and multigrain parallelizing compilers, and the surveyed technologies will be classified. Specific research compilers to be studied include Polaris, a loop parallelizing compiler developed by the University of Illinois, and OSCAR, a multigrain parallelizing compiler developed by Waseda University. Commercial compilers to be studied include KAP and PGI. These various technologies will be categorized and listed. Moreover, small-scale test programs will be used to evaluate the performance of each of the individual technologies classified, and program conditions necessary to evaluate the performance of individual parallelizing compilers will be examined.
2) Based on the results of the classification in 1) above, benchmark programs will be developed to evaluate the performance of each individual parallelization (optimization) technology. Consequently, benchmark programs for performance evaluation of each individual parallelization technology consisting of the aforementioned programs will be developed.
(2) Development of technologies to evaluate general performance
1) Existing scientific and engineering calculation programs are collected and a survey of the parallelization of these programs will be conducted. Actual application programs used in fields of scientific and engineering calculation such as fluid dynamics, atomic energy analysis and structural analysis are collected and parallels in the programs are analyzed. Parallels will be analyzed by conducting parallelization in actual programs using both research and commercial parallelizing compilers. With the results of these analyses, the conditions required of programs for the evaluation of general compiler performance will be examined.
2) Based on the results of the classification in 1) above, benchmark programs will be selected to intergrally evaluate the general compiler performance. Consequently, benchmark programs for general performance evaluation will be developed.
Many benchmark programs exist to evaluate the performance of the hardware in parallel computers, such as Linpack, SPEC, NAS Parallel Benchmarks and Splash. Using the results of these programs, performance evaluation methods are becoming established that indicate performance according to uniform measures. In the evaluation of parallelizing compiler performance, however, the situation is much less satisfactory. Some benchmark programs exist for evaluating loop parallelization performance, such as Perfect Benchmarks. A benchmark program capable of evaluating a wide range of parallelizing functions, such as is required for multigrain parallelizing compilers, is not yet available. For this reason each developer of conventional parallelizing compilers tends to use its own proprietary benchmark programs to evaluate compiler performance, and it is currently difficult to indicate the results of performance evaluations according to consistent and uniform evaluation measures.
In this project, benchmark programs will be developed to enable general performance to be compared among parallelizing compilers using consistent and uniform measures. These benchmark programs will be used to solve problems in the evaluation of performance in conventional parallelizing compilers.
When developing parallelizing compiler technology, questions such as what effect individual parallelization (optimization) technologies run in the compiler have on the program and in which portions problems may occur in parallelizing technology, must be analyzed in detail, to provide feedback in technology development. Evaluation of general parallelizing compiler performance is not sufficient to conduct this detailed analysis; evaluation of the performance of individual parallelizing technologies must be carried out as well. At the present time, however, the necessary methods of performance evaluation have not yet been established. By developing performance evaluation benchmarks for individual parallelization (optimization) technologies in parallelizing compilers, this project will establish performance evaluation technologies that make possible detailed analysis of parallelization (optimization) technology.
<Final target>
The final targets of this project are:
- To develop a suite of benchmark programs to evaluate the performance of individual technologies. This suite must be capable of evaluating the performance of each individual parallelization (optimization) technology in the parallelizing compiler.
- To develop a suite of benchmark programs to evaluate general performance. This suite must be capable of comparing parallelization performance in loop-parallelizing and multigrain-parallelizing compilers using uniform and consistent measures.
Currently, the results of performance evaluation using benchmark programs are widely accepted as an index of the running performance of computers. For example, benchmark programs such as SPEC are popular with hardware vendors, who use the running results as a common performance index for comparing the computers produced by each company. To establish their widespread acceptance in the evaluation of parallelizing compiler performance, therefore, it is important to develop benchmark programs that provide a common performance evaluation index, which is one of the final targets of this research and development project. In addition, to promote the improvement of parallelizing compiler technology, evaluation of the effectiveness of each optimization technology must be combined with consistent and uniform evaluation of overall performance in comparison with other compilers. Tools are therefore needed to provide technological support for the work of parallelizing compiler developers. The final target of this project is to fulfill this need develop benchmark program suites for the evaluation of the performance of individual technologies and for the evaluation of general performance.
1-3. Research and Development Plan
2. Research and Development Capability
2-1. Research and Development Track Record
The Aida Laboratory has been involved in parallelizing compiler research since 1992, particularly in the field of evaluation of performance in coarse-grain-level parallel processing, a key technology involved in multigrain parallel processing. In addition, since 1997 the Aida Laboratory has been conducting research on methods of performance evaluation for parallel and distributed processing technologies. Prof. Aida has published one academic paper, one international conference paper and one general lecture paper. His research results in automatic multigrain parallelizing compilers include four papers, three international conference papers and 16 general lecture papers.
2-2. Equipment Used in Research and Development
|
Type of Equipment
|
Details
|
|
Small-scale SMP computer
|
Dell Power Edge6300(4CPU)
|
|
Large-scale parallel computer
|
SGI Origin 2000
|
2-3. Effects of Research and Development on Industry
Parallel computing is today a widely used technology, adopted in systems from supercomputers to PCs. However, the pace at which adoption of this technology is spreading is disappointing. Factors impeding the spread of parallel computing include the difficulty of development of parallel programs and the poor effective performance of parallel computing. To solve these problems, the performance of parallelizing compiler must be improved.
This R&D project will enable:
- Evaluation of the performance of parallelizing compilers using uniform and consistent evaluation measures
- Detailed analysis of individual parallelizing technologies, leading to improvement of parallelizing compiler technology
The results of this research will strongly support developers' efforts to develop parallelizing compilers. The positive impact of this R&D will be felt not only in the software industry, where parallelizing compilers are developed, but in Japan's computer industry, where the improvement of parallelizing compiler performance will stimulate growth.
[2] FY 2000 Plan (first year)
|
1. Details of Research and Development (FY 2000)
In FY 2000, a survey is conducted of parallelizing technologies and scientific and engineering calculation applications needed for the development of performance evaluation technologies for individual technologies and for the development of general performance evaluation technologies. In parallel with this survey, work will begin on the development of related benchmark programs.
(1) Development of performance evaluation technologies for individual parallelization technologies
To develop performance evaluation technologies for individual parallelization technologies, existing parallelization technologies must first be surveyed and classified. In FY 2000, a survey is conducted of parallelization technologies realized on commercial and research parallelizing compilers, and these parallelization technologies are classified. Specific parallelization technologies studied in this phase are loop restructuring technologies, which are used in loop parallelization, and macrotask restructuring in macro data flow processing, which is a method of coarse-grain parallel processing. In the survey of loop restructuring technologies, in addition to a survey of research literature, programs compiled using compilers such as KAP, PGI and Polaris are run and evaluated on an SMP computer. In the survey of macrotask restructuring, the research literature is surveyed and programs are compiled using the OSCAR compiler.
Also in FY 2000, in parallel with the survey of parallelization technologies described above, examination will begin for the development of a suite of benchmark programs, to be used in evaluating the performance of individual parallelization technologies.
Considerable work has been done on benchmark programs for performance evaluation in loop parallelization technologies by groups such as the University of Illinois. However, no examination has yet been carried out on benchmark programs for performance evaluation in coarse-grain parallelization technology, such as macrotask-flow processing. The benchmark program suites that will begin to be examined in this fiscal year will break new ground by enabling performance evaluation in loop parallelization, coarse-grain parallelization and multigrain parallelization, which combines the first two.
(2) Development of technologies to evaluate general performance
Evaluation of overall performance in parallelizing compilers is conducted using the best possible scientific and technical computing applications for performance evaluation. In FY 2000, a survey of these scientific and technical computing applications will be conducted. After a suite of scientific and technical computing application programs that run on parallel computers is collected, parallel analysis is conducted in each of these programs. This program analysis consists of analysis by hand of the program source code as well as parallelization of the source program using existing parallelizing compilers.
Though many examples exist of surveys of scientific and technical computing applications from a loop-parallelization perspective, few examples can be found of surveys that combine the perspectives of loop parallelization and coarse-grain parallelization. In the present survey, results of program analysis will be collected from both perspectives.
In tandem with the survey of application programs described above, selection of benchmark programs will begin.
3 Research and Development Implementation Structure
|
1. Research Organization and Management System
1-1. Officers responsible for Research Implementation
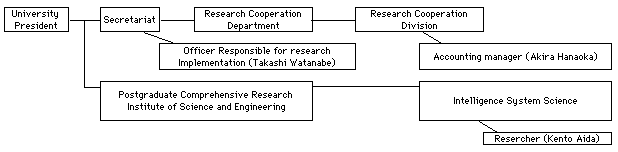
Officer Responsible for research Implementation: Takashi Watanabe, Director of Secretariat, Tokyo Institute of Technology
Accounting Manager: Akira Hanaoka, Research Cooperation Department, Research Cooperation Division, Tokyo Institute of Technology
1-2. Organization Chart
1-3. Research Locations
The Aida Laboratory, Intelligence System Studies, Postgraduate Comprehensive Research Institute of Science and Engineering, Tokyo Institute of Technology
4259 Nagatsudamachi, Midori-ku, Yokohama-city, Kanagawa (226-8502)
Available floor space 60m2
2. Names of Researchers
|
Name
|
Location and position
|
Main research track record and results
|
|
Kento Aida (Doctor of Engineering)
|
Lecturer, Intelligence System Studies of Postgraduate Comprehensive Research Institute of Science and Engineering, The University of Electro-Communications
|
- Kento Aida, Kiyoshi Ishikawa, Masami Okamoto, Hironori Kasahara, and Seinosuke Narita "Evaluation of the Performance of Fortran Coarse-grain Task Parallel Processing in Shared-memory Multiprocessor Systems," Journal of the Information Processing Society, Vol. 37 No.3, pp.418-429, March 1996
- Kento Aida, Kiyoshi Iwasaki, Hironori Kasahara, Seinosuke Narita, "Performance Evaluation of Macrodataflow Computation on Shared Memory Multiprocessors," Proc. of IEEE Pacific Rim Conference on Communications, Computers, and Signal Processing, pp. 50-54, 1995.05
- Masami Okamoto, Kaneto Aida, Minoru Miyazawa, Hiroki Honda, Hironori Kasahara, "A Hierarchical Macrodataflow Processing Method in the OSCAR Multigrain Compiler," Journal of the Information Processing Society, Vol. 35 No.4 pp.512-521, April 1994
|
|