2 FY 2000 Plan (First Year)
|
1. Details of Research and Development (FY 2000)
The following research and development activities will be carried out in FY 2000.
1-1. Development of Advanced Parallelizing Compiler Technology
1-1-1. Technology Trends
(a) Automatic multigrain parallelizing technology
Today's automatic parallelizing compilers for multiprocessor systems conduct parallelization on the loop-iteration level. Efforts are made to increase the number of parallelizable loops using data-sensitive analysis techniques such as the greatest-common-divisor (GCD) method, Banerjee's inexact and exact tests, the OMEGA test, symbolic analysis, semantic analysis and interprocedural analysis; and program restructuring (automatic program reconfiguration) technology such as loop distribution, loop fusion, strip mining, loop interchange and array privatization. For example, the University of Illinois in the United States aims to improve loop parallels in its Polaris compiler using in-line deployment of subroutines, symbolic propagation, array prozetazation and run-time data-sensitivity analysis. Similarly, researchers at Stanford University are working to streamline loop parallel processing in their SUIF compiler using interprocedural analysis, which analyzes data sensitivity between procedures; unimodular conversion, in which program restructuring is systematized through line conversion; and data locality optimization, which aims to make effective use of cache memory.
Thanks to these numerous research efforts involving loop-parallelizing compilers, efficient parallelization of many loops has been achieved. However, it is difficult to assign strict data sensitivity during compiling in cases such as loop-carried dependence, in which the data defined at the end of the previous iteration must be used at the beginning of the following iteration; loops with conditional branching, in which the loop is exited under certain conditions as in convergence calculations; or array indirect referencing, in which other array references are contained in the array subscripts in the loop. Loops such as these are processed serially in a single processor.
Although some 99% of program run time can be parallelized by advanced data-sensitive analysis and restructuring, the remaining 1% consists of parallel loops such as those described above, which are difficult to parallelize, or remain as portions outside the loop. In the latter case, boosting the number of processors from 1 to 1,000 results in only a 100-fold improvement in processing speed. This means that, though the problems posed by the 1% of the program that cannot be parallelized are negligible in single-processor systems, they become a serious obstacle to improvement of parallel processing performance as the number of processors increases. To improve the performance of the multiprocessor systems of the future, therefore, new parallelization techniques such as coarse-grain parallelization and near-fine-grain parallelization must added to loop parallelization.
In the PROMIS compiler, jointly developed by the University of Illinois and the University of California at Irvine, features of the former's Parafrase-2 are combined with features of the latter's Eve. From Parafrase-2, PROMIS gained the hierarchical task graph (HTG), an interface that displays parallels between tasks in a hierarchical fashion, as well as symbolic data-sensitive analysis technology. The PROMIS compiler benefited from the Eve project with the inclusion of instruction-level fine-grain parallel processing based on VLIW.The resulting compiler is capable of using parallels from multiple grains.
The NANOS compiler, based on Parafrase-2, is being developed to extract multilevel parallels, including coarse-grain parallels, using extended OpenMP API.
OpenMP can be simply described as a programming model for parallel programming in shared-memory multiprocessor systems. It is not a new parallel processing language but a means of extending and parallelizing existing languages such as Fortran, C and C++ by the addition of directives. Most of the work of examining specifications for OpenMP is done by American independent software vendors (ISVs), who released API version 1 API of OpenMP for Fortran in October 1997 and API version 1 for C/C++ in October 1998.
These specifications cannot be developed by a single computer manufacturer or software vendor. They must be decided through dialog among people in a large number of companies, exchanging ideas by e-mail. The background to this process is as follows. Various manufacturers have developed and marketed shared-memory multiprocessors and gained steadily expanding sales. Unfortunately, they failed to develop the compilers and tool suites needed to operate these systems efficiently. In particular, to run numerical calculation programs at high speed, compiler directives are often embedded in the source program to make compiler code generation easier. The problem here is that each company used to have its own specifications for compiler directives, such as SGI Power Fortran/C, SUN Impact and KAI/KAP. These specifications could not be transferred between multiprocessor systems, causing great confusion and inconvenience to the user. This issue gave rise to the move toward selection of a common API.
As suggested by its use of Fortran and C/C++ as base languages, the principal field of application of OpenMP is scientific and engineering calculation. The reason for this is that this discipline often uses parallel computing, and researchers in this area have generally needed to elicit the highest possible performance from their machines. Several language-specific reasons make these languages strong candidates for parallelization. First, scientific and engineering calculation programs tend to be relatively portable. Since the bulk of the work they do consists of calculation, few special I/O requests are made. Second, 5% of the code in programs such as these often takes up 95% of processing time. This makes parallelization easy, since significant gains can be realized by concentrating on only 5% of the code. Finally, the shared memory model is relatively convenient for porting and transferring of parallel programs.
(b) Parallelizing tuning technologies
The results of Stanford University's SUIF project offer a glimpse into recent R&D trends in compiler tuning tools. SUIF is at the heart of a parallelization support environment equipped with an interprocedural automatic parallelization function. At the University of Illinois, the Parafrase compiler is used as the heart of an interactive parallelization environment. Both of these systems are closely linked with the compiler and are closely watched for emerging trends in this field of research and development.
1) SUIF Explorer
SUIF is a compiler system being developed under the direction of Stanford University's Monica Lam. The compiler infrastructure of Lam's project has attracted widespread attention. The structure of SUIF Explorer is as follows.
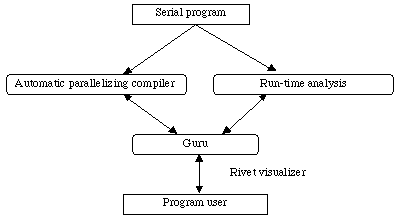
a. Automatic parallelization
SUIF Explorer has a function for interprocedural parallelization, based on the SUIF parallelizing compiler, which possesses a function for extracting coarse-grain parallels. An advanced program analysis function is enormously helpful to the user in tuning the program and is central to the interactive system as well. The reference regions used in array analysis adopt a method of expression that combines nonlinear inequal and pure-mathematics algorithms.
A great number of analytical methods have been proposed in the past, but a truly useful analytical method offers not just analytical precision but, with a view to commercialization, parsimonious use of analyzing time and memory capacity. Interactive systems in particular impose strong constraints on analyzing time. Future research efforts are expected to focus on finding effective combinations of various methods, as well as improving individual analytical methods. Because it is inefficient to try to solve all problems with a single method, it is important to combine a variety of methods as appropriate to each case.
b. Run-time analysis
The two key methods of run-time analysis are loop profile analysis and dynamic sensitivity analysis.
Loop profile analysis is a simple tool that searches for loops that are important in improving performance, providing an indispensable support function. As the program is run serially, the run time for each loop is measured as a percentage of the entire program, and average calculation time for each loop is determined. This collected information is then used to insert before and after each loop a measurement code, on which the run time is registered. This measurement requires very little time and creates no overhead.
Dynamic sensitivity analysis uses run-time-sensitivity analysis to calculate sensitivity during running, to determine whether loop parallelization is feasible or not. Read/write references are measured for this purpose and kept in a history that records the most recent write events for each memory reference in the program. Also, recursive variables and redactions identified by the compiler are identified, and the sensitivity of these variables are ignored. Dynamic sensitivity analysis uses close liaison with the compiler, as cases of parallelization using counterdependency and data privatization can also be identified. This dynamic analysis is extremely time-consuming but is highly effective in detecting parallels within programs. It is applied in setting targets for automatic parallelization in compilers and for evaluating parallelizing technology.
c. Performance improvement guidance
SUIF Explorer incorporates an interactive guidance function called Guru. Rather than simply display all of the analyzed compiler data and collected run-time data in raw form, Guru draws the user's attention to the most important loops and provides the user with the information necessary to perform parallelization and boost performance. Using Guru, the user can now perform effective parallelization armed with an understanding of how the program behaves, rather than a detailed knowledge of parallelization techniques.
Guru uses the following two quantitative measures to describe parallelization processes. These measures are commonly used to assess the effects of parallelization.
- Parallelization rate: Share of total run time consumed in running parallel regions
- Parallelization grains: Size of parallel processing units
d. Program slicing
Even when Guru focuses questions to the programmer to the level of determining whether a dependency exists between two memory references in a loop that is blocking parallelization, the programmer faces many difficulties in answering those questions. For example, it may be impossible search through the entire loop, or even outside the loop, to specify all of the code affected by the dependency. Not only is this work extremely troublesome and time-consuming, but it is prone to error as well.
To render this work more efficient, a concept called "program slicing" was introduced. Program slicing is a technique that filters out irrelevant code, automatically restricting the display to related code. This technique reduces complexity and improves the efficiency of tuning work. Clarity of the display method is a crucial issue, since without program slicing a dauntingly vast amount of data would be displayed, and combing this data for the relevant parts is a troublesome and unrewarding chore.
e. Visualization
SUIF Explorer renders programs visible using the Rivet visualization system. The Rivet system applies leading-edge visualization tools to computer system design, rendering complex computer system behavior easy to grasp.
The Rivet system uses the SimOS to visualize this simulation and the data gathered using the simulation in an interactive manner.
f. Directive checker
The directives inserted by the user are instructions for the compiler, and the compiler normally carries out processing according to these instructions. Sometimes an erroneous directive is inserted and optimization and parallelization are not carried out correctly, resulting in incorrect running.
To avoid this danger, the results of compile-time analysis and run-time data-sensitivity analysis are used by the directive checker to determine whether directives inserted by the user are correct or not. Because these results are highly sensitive to the analytical capability and run-time analytical capability of the compiler, they cannot be relied on to perform all necessary checks. With some oversight from the user, however, the directive checker is a powerful tool for preventing errors.
2) Parallelization environments in which the user and compiler interact
The SUIF Explorer described above is an example of an interactive parallelization tool based on an automatic parallelizing compiler. A different approach is exemplified by a graphical environment called the Graphic Parallelization Environment (GPE). GPE uses the concept of conducting the parallelizing compiling process through an interactive dialog with the user.
This system provides a visualization tool to combine user knowledge with compiler technologies, enabling the user to carry out the program parallelization process efficiently. The user must posses advanced knowledge of parallelization technology. At the core of GPE is Parafrase-2, the parallelizing compiler developed by the Center for Supercomputing Research and Development at the University of Illinois.
In GPE, all interaction between the user and the compiler is mediated by an abstract program display called a task graph.
a. Task graph
The task graph is a display format tailored to providing the user with a conceptual grasp of parallel running in the program. To provide the user with both a graphical format and a conceptual grasp of the process in a simple form, a hierarchical task graph is adopted. Code is divided into fragments according to natural boundaries such as statements, loops, subroutines and basic blocks. Loops consist of sub-units such as basic blocks or other loops.
b. GPE architecture
The basic approach of GPE is that program parallelization is the result of a cyclic tuning process, in which each tuning cycle is conducted under the same user environment.
The following is a summary of the series of operations and tools used in the tuning process.
1) Program editing and initial insertion of compiler directives (Jedit)
2) Compiling configuration and compiling (Jedit + Parafrase-2)
3) Program task graph and visualization of the dependency relationship between tasks (HTGviz)
4) Program task parallelization tuning: Task selection and insertion of OpenMP directives into the appropriate selected tasks (HTGviz)
5) Parallel code generation, measurement code selection and start of compiler code generation path, using task marking (HTGviz + Parafrase-2)
6) Program running (Jedit)
The user captures the running profile of the parallel codes in each of a series of tuning cycles, then uses that profile in the next cycle to achieve optimum parallelization.
c. Parallelizing compiler
Parafrase-2 is a multi-language-compatible compiler that conducts source-to-source structural conversion. Source programs written in any of several languages are expressed in the same way within the compiler to perform a wide variety of optimization, structural conversion and parallelization tasks. The results are then output in the language in which they were originally input. To achieve this, Parafrase-2 includes language-specific preprocessors and postprocessors. The preprocessor converts each language into the shared, compiler-internal expressions, and the postprocessor converts the internal expressions back into the input language. Although Parafrase-2 currently supports only C and Fortran, the compiler has been modified in PDE to handle OpenMP directives as well.
d. Editor
Jedit is a customizable X-windows text editor, provided as part of the Jtools package. This editor provides a function whereby OpenMP directives can easily be inserted into files during editing. To insert a directive into the text, the user simply selects a directive from a menu.
The most important functions of Jedit are compiler path configuration and control. The interface provides easy addition and deletion of compiler paths in the config set, as well as a way of specifying path arguments and options.
e. Task graph visualizer
HTGviz, the task graph visualizer, provides the following functions.
- HTGviz distributes tasks to grains specified by the user, indicates HTG structure across multiple levels and assigns code to HTG nodes.
- HTGviz analyzes the dependencies in the data and control flows between tasks in HTG and visualizes them, along with running restrictions.
- HTGviz visualizes program parallelization and the task running sequence within HTG.
As the explanation above demonstrates, the advantage of GPE is that it does not simply expose automatic parallelization processes at the surface but provides an interactive environment between the user and the compiler, and offers a rich user interface. However, although the target users are advanced users proficient in parallel processing, there are many levels of users, so a customization feature that can adapt to various user levels will be needed in the future.
1-1-2. Details of FY 2000 Research and Development
(1) Development of automatic multigrain parallelizing technology
(a) Multigrain parallel extraction technology
In FY 2000, the first year of this project, basic research and development will be conducted toward achievement of the final target: to achieve effective parallel processing using multigrain parallelizing technology on an SMP based on OpenMP. The most exceptional aspect of the multigrain parallelization technology in this project is the use of OpenMP to achieve automatic coarse-grain task parallel processing. This achievement will be the first of its kind in the world and will work on commercially available shared-memory multiprocessors.
This project is based on functions for generating coarse-grain tasks in units of subroutines and loops, as well as extraction of parallels from between coarse-grain tasks using first-possible-running conditions in previously developed multigrain parallelizing compilers. On this basis, a format will be developed for achieving coarse-grain parallel processing between tasks in one or two levels specified by the user, using OpenMP. Simple performance evaluation of the multigrain parallel extract technology will be conducted using SMP systems currently held by the researchers.
(b) Data-sensitive analysis technology
In conventional data-sensitive analysis, analysis of data-sensitive relationships is only conducted statically during compiling. Consequently, when variables that cannot be determined during compiling occur in array subscripts, data sensitivity has to be assumed to exist for safety's sake. As a result, in many cases parallels could be run but were mistakenly judged to be unparallelizable. In FY 2000, research and development into a data-flow analysis technology will be conducted. This technology will enable conditions for generation of data sensitivity between array references to be generated statically during compiling; those conditions can then be distinguished during running, and selection can be made during running between a parallelization code and a parallel code. In addition, the scope of parallelization technology will be expanded to include Fortran90 language specifications such as dynamic-arrays, shape succession and recursive calling, which are unavailable in conventional parallelization technologies.
(c) Automatic data distribution technology
1) Data distribution technology for DSM systems
Conventional automatic data distribution technology are unable to specify data distribution correctly if the message form of the array is different in the source that is calling a procedure and the procedure being called, or if only part of an array is referenced. In FY 2000, this project will conduct research and development in automatic data distribution technology for DSM, which will be able to distribute data correctly in DSM multiprocessors in cases such as these. The project will also survey the characteristics of software-based DSM and examine optimization measures for software-based DSM, as promising methods for delivering low-cost DSM.
2) Data distribution technology for distributed cache memory
When calculation and data distribution are conducted in conventional parallelization methods, the task grains are often too fine or forced sharing occurred, creating an increase in communication volume that prevents any performance gains. In FY 2000, a number of loop conversion technologies will be developed to achieve grain conversion in tasks, to obtain the appropriate grain size for each task. Also, data distribution technologies will be developed that provide data layout, to reduce cache errors such as fordced sharing.
3) Data distribution technology for multiprocessor systems with shared memory and local memory
In conventional multigrain parallelization using dynamic scheduling, data shared between coarse-grain tasks is generally allocated to a central, shared memory. To reduce the resulting overhead from data transfer ad raise the efficiency of parallel processing, this shared data must be distributed to local memory, so that data can be transferred through this local memory. In FY 2000, this project will develop an automatic data distribution technology that will transfer data between coarse-grain tasks through local memory, rather than through central shared memory as in conventional systems. Specifically, data and processing distribution methods and dynamic scheduling methods will be developed to transfer data through local memory in broad areas of programs, consisting of coarse-grain task sets with no conditional branching.
(d) Speculative running technology
In FY 2001, as part of the development of multigrain parallelization technology for R&D item 1), "APC technology," the project team will conduct:
- Development of algorithms to apply speculative running to coarse-grain tasks
- Examination of the extended parallel description language and interface
As part of R&D item 2), "technology to evaluate the performance of parallelizing compilers," the project team will conduct research and development in:
- Classification of methods of applying speculative running
(d-1) Classification of methods of applying speculative running
Two methods of speculative running that have been proposed for medium grains (loops) are thread-level data speculation and superthreading. In these methods, the loops are classified to clarify the target loops. First, the loop control portions are distinguished from the body portions. Speculative running is then classified to determine which loop control portions and which loop body portions are to be subjected to speculative running.
Loops are classified into two types. By applying speculative running to loop control portions, these portions are classified as loops that can be handled as conventional Doall and Doacross loops. Similarly, by applying speculative running, loops are classified as having dependent variables that enable delay d (delay in the start time of each iteration) in Doacross loops to be reduced.
(d-2) Development of algorithms for applying speculative running to medium grains
The "critical speculative running" proposed above consists of the following two steps:
1) Fusion of parts in which the effect of speculative running is slight, based on control sensitivity and data sensitivity between basic blocks
2) Code copying to create uniform data sensitivity, regardless of control sensitivity
This process enables macrotasks (MTs) to be made larger and avoids the problem of side-effects of speculative running. Also, by performing speculative running as conducted in VLIW and Superscalar, hierarchical speculative running is made feasible within and between MTs.
In multigrain parallel processing, the program is divided into blocks BPA, RB and SB, and parallels are extracted between tasks using coarse-grain parallel processing, medium-grain parallel processing, and near-fine-grain parallel processing. In applying critical speculative running to this multigrain parallel processing, it is necessary to select the portions in which the effect of speculative running will be the greatest.
For example, 99% of the calculation time in the compress program in SPECint95 consists of special while loops. To handle these loops, branching probability at time of running is used, and the types of dependencies on which speculative running is to be applied must be considered carefully.
In this R&D project, the application of speculative running to medium-grain tasks will be examined, in line with the policies described above.
(d-3) Examination of an interface for the extended parallel description language
In the course of the above research and development efforts, the data needed for analysis as program data will be listed and introduced into the extended parallel description language.
(e) Scheduling technology
In the multiprocessor systems of the near future, from SMPs to HPCs, one of the most critical issues will be to restrain the explosive growth in overhead from data transfer between processors, as the operating frequency of processors increases. The scheduling technology developed in this project will maximize the parallels analyzed in coarse-grain and near-fine-grain task sets, while reducing data transfer volumes, equalizing load between processors and overlapping with task processing any data transfer that cannot be eliminated. In FY 2000, heuristic scheduling algorithms will be proposed for incorporation as part of a compiler. Moreover, performance evaluation will be conducted using random-task graphs to provide objective evaluation of algorithm performance.
(2) Development of parallelizing tuning technology
(a) Program visualization technology
Conventional program visualization technology can specify which variables and arrays impede parallelization in portions of programs that are frequently run but cannot be parallelized. However, to examine the properties of these variables and arrays, programmers had to examine by hand large parts of the program, in an extremely time-consuming process. In FY 2000, program-slicing technology will be developed. This technology will summarize and extract portions involved in determining reference conditions and values for variables and arrays that impede parallelization, enabling easy retrieval of variables and arrays that impede parallelization.
1-2. Development of technologies for the evaluation of parallelizing compiler performance
1-2-1. Technological trends
Benchmarks (also called benchmark suites) are generally defined as benchmark programs plus the run rules by which they operate. In most cases benchmark programs are made available as source code.
Benchmark programs in use today can be broadly classified into three types as follows.
Kernel benchmark programs:
Vector calculation machines and initial parallel calculation machines are used to parallelize a single loop. Their performance is evaluated using kernel benchmark programs, which are incorporated into the portion of the program, focusing on loops that consume most of the run time. Principal examples of this type of benchmark are Livermore Loops, LINPACK and NAS kernels. Even today, these kernel benchmarks are frequently used in the evaluation of single-loop optimization and parallelization.
Full-scale application benchmark programs:
In many of today's parallel computers, however, parallelization is conducted across entire programs. It is now clear that kernel-type benchmarks are wholly inadequate to evaluate the performance of parallel computers in running applications. In particular, performance in transfer of data required when the optimal data allocation differs between kernels cannot be evaluated within a single kernel. In such cases it has become common to use a full-scale application program as the benchmark program.
Compact application benchmark programs
Despite the advantages listed above, the use of full-scale application programs as benchmark programs is fraught with the problems of copyright and the sheer size of the programs. An efficient solution is to extract several kernels with desired attributes from such full-scale applications to create a compact application, a program consisting of a few thousand lines at most. A compact application enables a programmer to evaluate performance with proficiency approaching that obtained using a full-scale application, and provides a way of focusing on particular aspects of the system, such as data communication performance and synchronizing overhead.
When using benchmark programs to measure performance, run rules are established to ensure that the results are fair and impartial. Generally information is published in the performance evaluation reports regarding the settings used to perform measurement.
- Tolerance for manual changes to the source code
- Tolerance for manual insertion of compiler directives in the source code
- Method of setting compiler options (types and extent of optimization/parallelization)
- Limits on the number of options that can be set
- Availability of a function to set optimum compiler options for each program
- Running environment
- Data size
- Number of processes
- Operating system environment (system tuning parameters such as single user/multiple users, stopping/starting of daemons and page size)
A number of indices are used to display the results of performance evaluation. The most common of these is program run time, but throughput may also be used. Although a simple display of time may be adopted, number of instructions run per unit of time may also be used as a means of displaying a comparison with the performance of a criterion computer. The following is a sample of some of the most common conventional benchmarks used performance evaluation in compiler-related research.
a. Perfect Benchmarks
Perfect Benchmarks (an acronym for "PERFormance Evaluation for Cost-effective Transformations) is a benchmark for technical and scientific calculations for high-performance supercomputing. Perfect Benchmarks is the product of development work between the University of Illinois' Center for Supercomputing Research and Development (CSRD) and a number of collaborating research facilities and private corporations. Begun in 1988, the finished benchmark was published in October 1993.
Perfect Benchmarks' benchmark programs consist of 13 application programs written in Fortran77. These programs were provided by the CSRD, IBM Kingston Laboratories, NASA Ames Laboratory, Princeton University, Cray Research and California Institute of Technology.
Performance is measured by comparing CPU time to run each program with wall-clock time. The result is used to calculate a value in millions of floating point operations per second, or MFLOPS.
This performance is measured in two ways. In the original (baseline) run, each program must be run as is, so only the absolute minimum manual changes in the code necessary to compile and run the program are permitted. Optimization using compilers and preprocessors is permitted, however.
In the second phase, step-by-step manual optimization of the source program is carried out. During this process, it is essential that an optimization diary be carefully recorded and reported, indicating what type of optimization is carried out, what improvement in performance was achieved and what kind of effort was required.
In measuring performance, the running environment for the benchmark programs consists of use by a single user. No daemons are used other than daemons absolutely essential for system operation.
To judge whether the results of the program run are correct, the values obtained as a result of running are compared with a previously prepared list of expected run results. A function is provided for examining whether the values obtained are within tolerance.
Perfect Benchmarks is a set of applications assembled in part by CSRD, an acknowledged leader in parallelizing compiler research, and is widely used as a benchmark program for evaluation purposes in the research work of researchers associated with CSRD. For these reasons the project team considers Perfect Benchmarks to be an appropriate set of benchmarks for use in evaluating the performance of automatic parallelizing compilers.
b. SPEChpc96
The Standard Performance Evaluation Corporation/High Performance Group (SPEC/HPG) began work on the development of SPEChpc96 in January 1994 and announced it in 1995 at the Supercomputing '95 trade exhibition. The key members of SPEC/HPG were the members of SPEC and a group of Perfect Benchmarks researchers. To these were later added researchers from the Parkbench, Seismic Benchmarks and other benchmark projects, as well as members from private industry and various research organizations. SPEChpc96 is a benchmark produced for the purpose of evaluating the performance of high-end parallel and distributed computers, and is capable of providing performance evaluation indices beyond simple measures of peak performance.
The benchmark programs of which SPEChpc96 is composed are numerical calculation programs used for processing on high-end computers in various industries and fields of research.
The benchmark programs in the current version of SPEChpc96 consist of three application programs written in Fortran and C. These programs are SPECseis96 and SPECchem96, which were part of the suite when SPEChpc96 was announced, and SPECclimate, which was added in 1998.
To measure performance, the time taken to run the benchmark program is measured. A value of 86,400 seconds (one day) for this run time is used as the SPEChpc96 benchmark index. At first glance it is easy to mistake this index as a simple indication of throughput, but it is important to note that it is in fact an indication of turnaround time.
When measuring performance, the person running the benchmark program can specify the state in which the system is run, but the state in which the measurement was carried out must be published.
When running the benchmark program, optimization of code is permitted only within a limited range. Permitted types of optimization are those within the capability of a general user operating a high-performance computer. These include manual rewriting of code, setting of compiler options (flags) and use of compiler directives (or language extensions). Any optimizations made must be published. Unlike SPEC CPU (see below), SPEChpc96 does not support measurement of baseline runs.
SPEChpc96 can run both serial and parallel programs, so this benchmark can be used to evaluate scalability from serial to parallel application. It can also be used to compare the running times of parallel programs with those of parallel programs compiled on a parallelizing compiler, which is expected to be useful in evaluating compiler performance.
c. SPEC CPU2000
Announced in December 1999, SPEC CPU2000 was developed by SPEC/OSG (The Stanford Performance Evaluation Corporation / Open System Group) as a successor to SPEC CPU89, SPEC CPU92 and SPEC CPU95. SPEC CPU95 is today one of the most commonly used benchmarks for commercial machines (processors). Key changes in the upgrade from SPEC CPU95 to SPEC CPU2000 are as follows.
- The run time for each benchmark program was made longer.
Due to progress in the speed of computer systems, benchmark programs ended too quickly under SPEC CPU95. SPEC CPU2000 was fixed to make run time sufficiently long even when running on newer systems.
- Problem sizes in each benchmark programs were made larger.
SPEC CPU95 had failed to reflect the recent increase in size and complexity of actual application programs. The problem sizes in SPEC CPU2000 were therefore increased.
- The total number of benchmark programs was increased.
SPEC CPU2000 was designed to evaluate overall performance, including the processor, memory and compiler. It cannot be used to evaluate performance of I/O, networks or graphics.
Whereas CINT2000 consisted of 12 application programs, SPEC CPU2000 included 14 application programs. This wide range of programs included in the benchmark is a unique feature of SPEC CPU2000.
These application programs were selected in consideration of the following factors.
- Program portability among different hardware and operating systems is high.
- The programs do not involve a great deal of I/O processing.
- They do not involve networking or graphics.
- They can operate on 256MB of main RAM without swapping.
- Run time spent on portions other than the code supplied by SPEC is 5% or less of total run time.
Generally speaking, the performance of computer systems tends to use system speed (turnaround time) and throughput. SPEC CPU2000 also measures these items, displaying the results as "none-rate (speed)" and "rate (throughput)."
When a parallelizing compiler is used to run one program on several compilers, the results appear as "none-rate." SPEC CPU2000 clearly indicates that the results were obtained from parallel processing.
SPEC CPU2000 has highly detailed rules on the compiler options (optimization flags) that can be set when using this program to compile source code. Two ways of evaluating performance are provided, using two different indices to display results, depending on the means of setting options. The first of these is the base index. In the base index, four compiler options can be set optionally for measurement, but all benchmark programs must be set to the same options. This index is intended for users who are not interested in optimization but simply wish to run the compiler as is. It is a required index for measurement result reports. The second index is the no-base (peak, aggressive compilation) index. The no-base index sets no limits on the number of compiler options that can be set, and different options can be set for different programs. This index is intended for users who wish to perform aggressive optimization on their programs, and is optional for inclusion in measurement result reports.
SPEC CPU is a widely used benchmark, applied not only in the parallel processing field but in general computing, workstations and PCs as well. Performance evaluations of parallelizing compilers conducted on SPEC CPU are fairly easy for general users to compare and understand.
d. NAS Parallel Benchmarks (NPB)
NPB is a benchmark provided by the Numerical Aerospace Simulation (NAS) program of NASA Ames Research Center to evaluate the performance of parallel supercomputers. This benchmark was created for the purpose of evaluating the performance of distributed-memory massively parallel computers in solving computational fluid dynamics (CFD) problems, as part of NASA's project to develop an aerospace vehicle for the 21st century.
NPB 1.0 was developed in 1991. NPB's unique feature as a benchmark is that only the specifications of the problem to be solved are stipulated; data structure, algorithms and programming are performed by the person performing the implementation. NPB's benchmark programs simulate the calculations and data transfer performed by CFD programs. Accordingly, NPB consists of three virtual applications that reproduce the data transfer and calculation within the CFD code and in the five parallel kernels at the core of five calculation methods used in the CFD program.
NPB is strictly focused on a single application program. It is used to perform detailed evaluation of the processing performance of each portion of that application.
e. PARKBENCH
PARallel Kernels and BENCHmarks (PARKBENCH) developed as a comprehensive parallel processing benchmark. Work on the project began when the PARKBENCH Committee was formed in 1992, and the benchmark was announced in 1993. Originally designed to evaluate the performance of distributed-memory machines, PARKBENCH used benchmark programs described in Fortran77 and PVM. In the current version, MPI programs are also included.
PARKBENCH consists of 10 low-level benchmark programs, used to evaluate basic system performance; seven kernel benchmark programs, including NPB's FT/MG; and four compact applications, including NPB-CFD's LU/ST/BT).
An HPF compiler benchmark is appended to PARKBENCH. This compiler benchmark, which comprises 10 kernel benchmarks, is used to evaluate the running of special syntax elements in HPF such as forall and independent.
PARKBENCH uses three types of benchmark programs to evaluate system performance. Its distinguishing feature is its use of an anatomical approach to performance evaluation.
1-2-2. FY 2000 Details of Research and Development
In FY 2000, the following research and development activities are to be carried out with respect to the existing benchmarks described in 1-2-1.
(1) Development of methods of evaluation of individual functions
One of the most widely adopted approaches to evaluation of the performance of computer systems consists of measuring the run time of a benchmark program on an actual machine. Unfortunately none of the benchmarks now available specifically focus on evaluating the performance of parallelizing compilers, so evaluation of parallelizing compiler performance has to be conducted using benchmarks that evaluate the performance of the CPU, the entire system, or parts thereof. Although the use of such benchmarks to measure the performance of compilers is not inappropriate in itself, the criteria by which benchmarks are selected are still vague. Consequently, the information published in performance evaluation reports on the run rules and the setting of conditions is never sufficient. Moreover, the contributions of individual functions to the performance of the compiler cannot always be readily identified.
A survey will be conducted of the various benchmarks currently diverted for the evaluation of performance in individual functions of parallelizing compilers. Through this survey, guidelines will be clarified for 1) selection of kernel and compact-application benchmark programs, 2) setting of run rules and 3) setting of measurement indices in evaluating the performance of individual functions of parallelizing compilers. Finally, a survey will be conducted of the individual functions of existing parallelizing compilers to clarify the current state of the technology. This effort will clarify the orientation of development to ensure that the resulting benchmark is an appropriate target for technological development and will promote the development of related technology.
Technology issues in ensuring that the benchmark is appropriate for evaluating the performance of the individual functions
|
Technology items
|
Conventional technologies
|
Key issues
|
Technology that clarifies the relationship with the program
|
Failed to clarify which portions of the program the individual functions were effective in
|
Technology to indicate qualitatively and quantitatively which individual functions are effective in which portions of the program
|
|
Technology that clarifies the relationship with other individual functions
|
Failed to clarify the relationship with other individual functions
|
Technology that conducts evaluation with minimum impact on other individual functions and indicates what impact it has on other individual functions.
|
|
Technology that clarifies the relationship with the hardware
|
Failed to clarify the degree of sensitivity to the hardware
|
Technology that conducts evaluation of hardware-insensitive individual functions with minimum impact on hardware and indicates what impact it has on the hardware
|
(2) Development of general performance evaluation methods
One of the most widely adopted approaches to evaluation of the performance of computer systems consists of measuring the run time of a benchmark program on an actual machine. Unfortunately none of the benchmarks now available specifically focus on evaluating the performance of parallelizing compilers, so evaluation of parallelizing compiler performance has to be conducted using benchmarks that evaluate the performance of the CPU, the entire system, or parts thereof. Although the use of such benchmarks to measure the performance of compilers is not inappropriate in itself, the criteria by which benchmarks are selected are still vague. Consequently, the information published in performance evaluation reports on the run rules and the setting of conditions is never sufficient. Moreover, the contributions of individual functions to the performance of the compiler cannot always be readily identified.
A survey will be conducted of the various benchmarks currently diverted for the evaluation of general performance of parallelizing compilers. Through this survey, guidelines will be clarified for 1) selection of compact-application and full-scale-application benchmark programs, 2) setting of run rules and 3) setting of measurement indices in evaluating the general performance of parallelizing compilers. Finally, a survey will be conducted of existing parallelizing compilers to clarify the current state of the technology. This effort will clarify the orientation of development to ensure that the resulting benchmark is an appropriate target for technological development and will promote the development of related technology.
Technology issues in ensuring that the benchmark is appropriate for evaluating general performance
|
Technology items
|
Conventional technologies
|
Key issues
|
Technology that performs hardware-insensitive performance evaluation
|
Performance evaluation includes the hardware
|
Technology that clearly distinguishes hardware-dependent portions from hardware-independent portions and uses actual applications to evaluate the performance of the compiler
|
|
Technology for fair and impartial comparison of compiler performance
|
Benchmark targets only specific programs
|
Technology that embraces program portions in which the individual functions of various compilers are expected to have an effect
|